实验题目
ucore lab4 内核线程管理
实验目的
- 了解内核线程创建/执行的管理过程
- 了解内核线程的切换和基本调度过程
实验内容
实验2/3完成了物理和虚拟内存管理,这给创建内核线程(内核线程是一种特殊的进程)打下了提供内存管理的基础。当一个程序加载到内存中运行时,首先通过ucore OS的内存管理子系统分配合适的空间,然后就需要考虑如何分时使用CPU来“并发”执行多个程序,让每个运行的程序(这里用线程或进程表示)“感到”它们各自拥有“自己”的CPU。
本次实验将首先接触的是内核线程的管理。内核线程是一种特殊的进程,内核线程与用户进程的区别有两个:
- 内核线程只运行在内核态
- 用户进程会在在用户态和内核态交替运行
- 所有内核线程共用ucore内核内存空间,不需为每个内核线程维护单独的内存空间
- 而用户进程需要维护各自的用户内存空间
相关原理介绍可看附录B:【原理】进程/线程的属性与特征解析。
练习0:填写已有实验
本实验依赖实验1/2/3。请把你做的实验1/2/3的代码填入本实验中代码中有“LAB1”,“LAB2”,“LAB3”的注释相应部分。
根据前面做的 lab1 和 lab2(包括扩展练习),我们可以知道总共有五个文件需要修改和填写:
- default_pmm.c
- pmm.c
- swap_fifo.c
- vmm.c
- trap.c
在终端输入 meld ,使用 meld 用之前的文件来对 lab4 中的文件进行修改和填写(当然也可以直接手动修改,但是不是很推荐,因为可能会漏掉一些地方)
这里以 default_pmm.c 为例进行演示
在终端执行以下命令:
1
meld
选择比较 lab3 和 lab4 的目录,找到那些需要填写的文件
选择 lab2 中的 default_pmm.c 和 lab3 中的default_pmm.c 进行比较
点击左边文件的箭头,并且删除右边文件中右箭头的代码块,使 lab3 中的 default_pmm.c 和 lab2 中的 default_pmm.c 一致
最后出现如下效果:
最后再保存即可,其他四个文件也按照如此步骤进行即可(不是一定要完全一样,只要在 lab1 和 lab2 写过的地方一样即可)
练习1:分配并初始化一个进程控制块
alloc_proc函数(位于kern/process/proc.c中)负责分配并返回一个新的struct proc_struct结构,用于存储新建立的内核线程的管理信息。ucore需要对这个结构进行最基本的初始化,你需要完成这个初始化过程。
【提示】在alloc_proc函数的实现中,需要初始化的proc_struct结构中的成员变量至少包括:state/pid/runs/kstack/need_resched/parent/mm/context/tf/cr3/flags/name。
请在实验报告中简要说明你的设计实现过程。请回答如下问题:
- 请说明proc_struct中
struct context context和struct trapframe *tf成员变量含义和在本实验中的作用是啥?(提示通过看代码和编程调试可以判断出来)
proc_struct 数据结构分析
在实验四中,进程管理信息用struct proc_struct表示,在kern/process/proc.h中定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
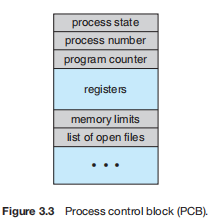
struct proc_struct {
enum proc_state state; // Process state
int pid; // Process ID
int runs; // the running times of Proces
uintptr_t kstack; // Process kernel stack
volatile bool need_resched; // need to be rescheduled to release CPU?
struct proc_struct *parent; // the parent process
struct mm_struct *mm; // Process's memory management field
struct context context; // Switch here to run process
struct trapframe *tf; // Trap frame for current interrupt
uintptr_t cr3; // the base addr of Page Directroy Table(PDT)
uint32_t flags; // Process flag
char name[PROC_NAME_LEN + 1]; // Process name
list_entry_t list_link; // Process link list
list_entry_t hash_link; // Process hash list
};
下面重点解释一下几个比较重要的成员变量:
● mm:内存管理的信息,包括内存映射列表、页表指针等。mm成员变量在lab3中用于虚存管理。但在实际OS中,内核线程常驻内存,不需要考虑swap page问题,在lab5中涉及到了用户进程,才考虑进程用户内存空间的swap page问题,mm才会发挥作用。所以在lab4中mm对于内核线程就没有用了,这样内核线程的proc_struct的成员变量mm=0是合理的。mm里有个很重要的项pgdir,记录的是该进程使用的一级页表的物理地址。由于mm=NULL,所以在proc_struct数据结构中需要有一个代替pgdir项来记录页表起始地址,这就是proc_struct数据结构中的cr3成员变量。
● state:进程所处的状态。
● parent:用户进程的父进程(创建它的进程)。在所有进程中,只有一个进程没有父进程,就是内核创建的第一个内核线程idleproc。内核根据这个父子关系建立一个树形结构,用于维护一些特殊的操作,例如确定某个进程是否可以对另外一个进程进行某种操作等等。
● context:进程的上下文,用于进程切换(参见switch.S)。在 uCore中,所有的进程在内核中也是相对独立的(例如独立的内核堆栈以及上下文等等)。使用 context 保存寄存器的目的就在于在内核态中能够进行上下文之间的切换。实际利用context进行上下文切换的函数是在kern/process/switch.S中定义switch_to。
● tf:中断帧的指针,总是指向内核栈的某个位置:当进程从用户空间跳到内核空间时,中断帧记录了进程在被中断前的状态。当内核需要跳回用户空间时,需要调整中断帧以恢复让进程继续执行的各寄存器值。除此之外,uCore内核允许嵌套中断。因此为了保证嵌套中断发生时tf 总是能够指向当前的trapframe,uCore 在内核栈上维护了 tf 的链,可以参考trap.c::trap函数做进一步的了解。
● cr3: cr3 保存页表的物理地址,目的就是进程切换的时候方便直接使用 lcr3实现页表切换,避免每次都根据 mm 来计算 cr3。mm数据结构是用来实现用户空间的虚存管理的,但是内核线程没有用户空间,它执行的只是内核中的一小段代码(通常是一小段函数),所以它没有mm 结构,也就是NULL。当某个进程是一个普通用户态进程的时候,PCB 中的 cr3 就是 mm 中页表(pgdir)的物理地址;而当它是内核线程的时候,cr3 等于boot_cr3。而boot_cr3指向了uCore启动时建立好的饿内核虚拟空间的页目录表首地址。
● kstack: 每个线程都有一个内核栈,并且位于内核地址空间的不同位置。对于内核线程,该栈就是运行时的程序使用的栈;而对于普通进程,该栈是发生特权级改变的时候使保存被打断的硬件信息用的栈。uCore在创建进程时分配了 2 个连续的物理页(参见memlayout.h中KSTACKSIZE的定义)作为内核栈的空间。这个栈很小,所以内核中的代码应该尽可能的紧凑,并且避免在栈上分配大的数据结构,以免栈溢出,导致系统崩溃。kstack记录了分配给该进程/线程的内核栈的位置。主要作用有以下几点。首先,当内核准备从一个进程切换到另一个的时候,需要根据kstack 的值正确的设置好 tss (可以回顾一下在实验一中讲述的 tss 在中断处理过程中的作用),以便在进程切换以后再发生中断时能够使用正确的栈。其次,内核栈位于内核地址空间,并且是不共享的(每个线程都拥有自己的内核栈),因此不受到 mm 的管理,当进程退出的时候,内核能够根据 kstack 的值快速定位栈的位置并进行回收。uCore 的这种内核栈的设计借鉴的是 linux 的方法(但由于内存管理实现的差异,它实现的远不如 linux 的灵活),它使得每个线程的内核栈在不同的位置,这样从某种程度上方便调试,但同时也使得内核对栈溢出变得十分不敏感,因为一旦发生溢出,它极可能污染内核中其它的数据使得内核崩溃。如果能够通过页表,将所有进程的内核栈映射到固定的地址上去,能够避免这种问题,但又会使得进程切换过程中对栈的修改变得相当繁琐。感兴趣的同学可以参考 linux kernel 的代码对此进行尝试。
为了管理系统中所有的进程控制块,uCore维护了如下全局变量(位于kern/process/proc.c):
● static struct proc *current:当前占用CPU且处于“运行”状态进程控制块指针。通常这个变量是只读的,只有在进程切换的时候才进行修改,并且整个切换和修改过程需要保证操作的原子性,目前至少需要屏蔽中断。可以参考 switch_to 的实现。
● static struct proc *initproc:本实验中,指向一个内核线程。本实验以后,此指针将指向第一个用户态进程。
● static list_entry_t hash_list[HASH_LIST_SIZE]:所有进程控制块的哈希表,proc_struct中的成员变量hash_link将基于pid链接入这个哈希表中。
● list_entry_t proc_list:所有进程控制块的双向线性列表,proc_struct中的成员变量list_link将链接入这个链表中。
可以看到,其实这里我们需要初始化的一个东西就是proc_struct的一个对象,分配的是一个内核线程的PCB,它通常只是内核中的一小段代码或者函数,没有用户空间。而由于在操作系统启动后,已经对整个核心内存空间进行了管理,所以内核中的所有线程都不需要再建立各自的页表,只需共享这个核心虚拟空间就可以访问整个物理内存了。(这里需要指出的一个重点是,虽然名字叫做内核线程,但是内核线程是一种特殊的进程,来自指导书P167)
完成 alloc_proc 函数
在实验指导书上有以下提示
【提示】在alloc_proc函数的实现中,需要初始化的proc_struct结构中的成员变量至少包括:state/pid/runs/kstack/need_resched/parent/mm/context/tf/cr3/flags/name。
并且在 alloc_proc 函数里有注释提示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
/*
* below fields in proc_struct need to be initialized
* enum proc_state state; // Process state
* int pid; // Process ID
* int runs; // the running times of Proces
* uintptr_t kstack; // Process kernel stack
* volatile bool need_resched; // bool value: need to be rescheduled to release CPU?
* struct proc_struct *parent; // the parent process
* struct mm_struct *mm; // Process's memory management field
* struct context context; // Switch here to run process
* struct trapframe *tf; // Trap frame for current interrupt
* uintptr_t cr3; // CR3 register: the base addr of Page Directroy Table(PDT)
* uint32_t flags; // Process flag
* char name[PROC_NAME_LEN + 1]; // Process name
*/
根据这两个提示我们可以知道要在这个函数里初始化哪些变量
我们在指导书中看到创建第 0 个内核线程 idleproc 的过程
在init.c::kern_init函数调用了proc.c::proc_init函数。proc_init函数启动了创建内核线程的步骤。首先当前的执行上下文(从kern_init 启动至今)就可以看成是uCore内核(也可看做是内核进程)中的一个内核线程的上下文。为此,uCore通过给当前执行的上下文分配一个进程控制块以及对它进行相应初始化,将其打造成第0个内核线程 – idleproc。具体步骤如下:
首先调用alloc_proc函数来通过kmalloc函数获得proc_struct结构的一块内存块-,作为第0个进程控制块。并把proc进行初步初始化(即把proc_struct中的各个成员变量清零)。但有些成员变量设置了特殊的值,比如:
1
2
3
4
proc->state = PROC_UNINIT; 设置进程为“初始”态
proc->pid = -1; 设置进程pid的未初始化值
proc->cr3 = boot_cr3; 使用内核页目录表的基址
...
上述三条语句中,第一条设置了进程的状态为“初始”态,这表示进程已经 “出生”了,正在获取资源茁壮成长中;第二条语句设置了进程的pid为-1,这表示进程的“身份证号”还没有办好;第三条语句表明由于该内核线程在内核中运行,故采用为uCore内核已经建立的页表,即设置为在uCore内核页表的起始地址boot_cr3。后续实验中可进一步看出所有内核线程的内核虚地址空间(也包括物理地址空间)是相同的。既然内核线程共用一个映射内核空间的页表,这表示内核空间对所有内核线程都是“可见”的,所以更精确地说,这些内核线程都应该是从属于同一个唯一的“大内核进程”—uCore内核。
所以我们可以得出 state、pid、cr3 的初始值
1
2
3
proc->state = PROC_UNINIT; 设置进程为“初始”态
proc->pid = -1; 设置进程pid的未初始化值
proc->cr3 = boot_cr3; 使用内核页目录表的基址
对于其他成员变量中占用内存空间较大的,可以考虑使用 memset 函数进行初始化,完成的函数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
static struct proc_struct *
alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
//LAB4:EXERCISE1 YOUR CODE
/*
* below fields in proc_struct need to be initialized
* enum proc_state state; // Process state
* int pid; // Process ID
* int runs; // the running times of Proces
* uintptr_t kstack; // Process kernel stack
* volatile bool need_resched; // bool value: need to be rescheduled to release CPU?
* struct proc_struct *parent; // the parent process
* struct mm_struct *mm; // Process's memory management field
* struct context context; // Switch here to run process
* struct trapframe *tf; // Trap frame for current interrupt
* uintptr_t cr3; // CR3 register: the base addr of Page Directroy Table(PDT)
* uint32_t flags; // Process flag
* char name[PROC_NAME_LEN + 1]; // Process name
*/
proc->state = PROC_UNINIT; //设置进程为未初始化状态
proc->pid = -1; //未初始化的的进程id为-1
proc->runs = 0; //初始化时间片
proc->kstack = 0; //内存栈的地址
proc->need_resched = 0; //是否需要调度设为不需要
proc->parent = NULL; //父节点设为空
proc->mm = NULL; //虚拟内存设为空
memset(&(proc->context), 0, sizeof(struct context));//上下文的初始化
proc->tf = NULL; //中断帧指针置为空
proc->cr3 = boot_cr3; //页目录设为内核页目录表的基址
proc->flags = 0; //标志位
memset(proc->name, 0, PROC_NAME_LEN);//进程名
}
return proc;
}
问题回答
1. 请说明proc_struct中struct context context和struct trapframe *tf成员变量含义和在本实验中的作用是啥?(提示通过看代码和编程调试可以判断出来)
其实这个问题在之前的数据结构分析中就已经说过了
首先看到 context 的数据结构:
1
2
3
4
5
6
7
8
9
10
struct context {
uint32_t eip;
uint32_t esp;
uint32_t ebx;
uint32_t ecx;
uint32_t edx;
uint32_t esi;
uint32_t edi;
uint32_t ebp;
};
再看到 trapframe 的数据结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
struct trapframe {
struct pushregs tf_regs;
uint16_t tf_gs;
uint16_t tf_padding0;
uint16_t tf_fs;
uint16_t tf_padding1;
uint16_t tf_es;
uint16_t tf_padding2;
uint16_t tf_ds;
uint16_t tf_padding3;
uint32_t tf_trapno;
/* below here defined by x86 hardware */
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding4;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding5;
} __attribute__((packed));
-
成员变量含义:
struct context中用于记录进程执行的上下文,也就是进程执行中的寄存器状态,在进程切换的时候会保存和恢复这些值。主要是在内核态切换到内核态或者用户态切换到用户态的进程调度的时候使用。- 而
tf指向的是中断帧的指针,指向内核栈的某个位置,用来在进程执行中发生中断时保存中断现场用,例如在用户态中断到内核态的时候。
-
作用:
以
kernel_thread函数为例,尽管该函数设置了proc->trapframe,但在fork函数中的copy_thread函数里,程序还会设置proc->context。两个上下文看上去好像冗余,但实际上两者所分的工是不一样的。进程之间通过进程调度来切换控制权,当某个
fork出的新进程获取到了控制流后,首当其中执行的代码是current->context->eip所指向的代码,此时新进程仍处于内核态,但实际上我们想在用户态中执行代码,所以我们需要从内核态切换回用户态,也就是中断返回。此时会遇上两个问题:- 新进程如何执行中断返回? 这就是
proc->context.eip = (uintptr_t)forkret的用处。forkret会使新进程正确的从中断处理例程中返回。 - 新进程中断返回至用户代码时的上下文为? 这就是
proc_struct->tf的用处。中断返回时,新进程会恢复保存的trapframe信息至各个寄存器中,然后开始执行用户代码。
可以看到两者在创建新进程的时候共同合作
- 新进程如何执行中断返回? 这就是
练习2:为新创建的内核线程分配资源
创建一个内核线程需要分配和设置好很多资源。kernel_thread函数通过调用do_fork函数完成具体内核线程的创建工作。do_kernel函数会调用alloc_proc函数来分配并初始化一个进程控制块,但alloc_proc只是找到了一小块内存用以记录进程的必要信息,并没有实际分配这些资源。ucore一般通过do_fork实际创建新的内核线程。do_fork的作用是,创建当前内核线程的一个副本,它们的执行上下文、代码、数据都一样,但是存储位置不同。在这个过程中,需要给新内核线程分配资源,并且复制原进程的状态。你需要完成在kern/process/proc.c中的do_fork函数中的处理过程。它的大致执行步骤包括:
- 调用alloc_proc,首先获得一块用户信息块。
- 为进程分配一个内核栈。
- 复制原进程的内存管理信息到新进程(但内核线程不必做此事)
- 复制原进程上下文到新进程
- 将新进程添加到进程列表
- 唤醒新进程
- 返回新进程号
请在实验报告中简要说明你的设计实现过程。请回答如下问题:
- 请说明ucore是否做到给每个新fork的线程一个唯一的id?请说明你的分析和理由。
完成 do_fork 函数
第一步:调用alloc_proc()函数申请内存块,如果失败,直接返回处理,相关的解释是,alloc_proc()函数在练习一中实现过,如果分配进程PCB失败,也就是说,进程一开始就是NULL,那么就会被if(proc!=NULL)判定为否,那么就不会分配初始化资源,连初始化资源都没有了,那么就会返回NULL,因此第一步这么处理,代码实现如下:
1
2
3
4
if ((proc = alloc_proc()) == NULL) {
goto fork_out;
}
第二步:将子进程的父节点设置为当前进程,这个没什么好解释的,直接用就可以,只需要注意一点,就是代表当前进程的变量current已经在全局定义(第76行),因此代码实现如下:
1
proc->parent = current;
第三步:调用setup_stack()函数(proc.c235行)为进程分配一个内核栈,根据注释,我们需要使用setup_kstack这个函数,它的解释:alloc pages with size KSTACKPAGE as process kernel stack,正是一个为函数分配一个内核栈的调用,因此,我们找到代码中对应的函数有如下分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
static int setup_kstack(struct proc_struct *proc) { //246行
struct Page *page = alloc_pages(KSTACKPAGE);
if (page != NULL) {
proc->kstack = (uintptr_t)page2kva(page);
return 0;
}
return -E_NO_MEM;
}
我们看到,如果页不为空的时候,会return 0,也就是说分配内核栈成功了(这样推测的根据在于,最后一个return -E_NO_MEM,大概推测就是一个初始化的或者错误的状态,因为在这个函数最开始不需要实现的部分,这个值就赋值给了ret),那么就会返回0,否则返回一个奇怪的东西。
因此,我们调用该函数分配一个内核栈空间,并判断是否分配成功,代码实现如下:
1
2
3
4
5
if (setup_kstack(proc) != 0) {
goto bad_fork_cleanup_proc;
}
第四步:调用copy_mm()函数(proc.c253行)复制父进程的内存信息到子进程,那么首先来看copy函数如下:
1
2
3
4
5
6
7
8
9
copy_mm(uint32_t clone_flags, struct proc_struct *proc) { //253行
assert(current->mm == NULL);
/* do nothing in this project */
return 0;
}
这个函数的注释解释是:进程proc复制还是共享当前进程current,是根据clone_flags来决定的,如果是clone_flags & CLONE_VM(为真),那么就可以拷贝。这个函数里面似乎没有做任何事情,仅仅是确定了一下current当前进程的虚拟内存是否为空,那么具体的操作,只需要传入它所需要的clone_flag就可以,其余事情不需要我们去做,代码实现如下:
1
2
3
4
5
if (copy_mm(clone_flags, proc) != 0) {
goto bad_fork_cleanup_kstack;
}
第五步:调用copy_thread()函数复制父进程的中断帧和上下文信息,那么观察相应的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) {
proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1;
*(proc->tf) = *tf;
proc->tf->tf_regs.reg_eax = 0;
proc->tf->tf_esp = esp;
proc->tf->tf_eflags |= FL_IF;
proc->context.eip = (uintptr_t)forkret;
proc->context.esp = (uintptr_t)(proc->tf);
}
需要传入的三个参数,第一个是比较熟悉,练习一中已经实现的PCB模块proc结构体的对象,第二个参数,是一个栈,判断的依据是它的数据类型,在练习一中的PCB模块中,为栈定义的数据类型就是uintptr_t,第三个参数也很熟悉,它是练习一PCB中的中断帧的指针,因为这些内容都和实验23相关,故这个函数只要调用,不再深究内部原理。
第六步:将新进程添加到进程的(hash)列表中,我们看到题目中注释给出了提示:
hash_proc: add proc into proc hash_list,意思是调用这个函数可以将当前的新进程添加到进程的哈希列表中,分析hash函数的特点,直接调用hash(proc)即可:
1
2
3
4
5
hash_proc(struct proc_struct *proc) {
list_add(hash_list + pid_hashfn(proc->pid), &(proc->hash_link));
}
函数的实现如下:(local intr函数的作用,在后面解释)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
bool intr_flag;
local_intr_save(intr_flag);
{
proc->pid = get_pid();
hash_proc(proc); //建立映射
nr_process ++; //进程数加1
list_add(&proc_list, &(proc->list_link));//将进程加入到进程的链表中
}
local_intr_restore(intr_flag);
步骤七:唤醒子进程
1
wakeup_proc(proc);
步骤八:返回子进程的pid
1
ret = proc->pid;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//下面的部分已经给出,不需要自己实现
fork_out:
return ret;
bad_fork_cleanup_kstack:
put_kstack(proc);
bad_fork_cleanup_proc:
kfree(proc);
goto fork_out;
}
完整的do_fork函数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
int do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf) {
int ret = -E_NO_FREE_PROC;
struct proc_struct *proc;
if (nr_process >= MAX_PROCESS) {
goto fork_out;
}
ret = -E_NO_MEM;
//上面的部分已经给出,不需要自己实现
//第一步:调用alloc_proc()函数申请内存块,如果失败,直接返回处理
if ((proc = alloc_proc()) == NULL) {
goto fork_out;
}
//第二步:将子进程的父节点设置为当前进程,
proc->parent = current;
//第三步:调用setup_stack()函数为进程分配一个内核栈
if (setup_kstack(proc) != 0) {
goto bad_fork_cleanup_proc;
}
//第四步:调用copy_mm()函数复制父进程的内存信息到子进程
if (copy_mm(clone_flags, proc) != 0) {
goto bad_fork_cleanup_kstack;
}
//第五步:调用copy_thread()函数复制父进程的中断帧和栈指针
copy_thread(proc, stack, tf);
//第六步:将新进程添加到进程的(hash)列表中
bool intr_flag;
local_intr_save(intr_flag);//屏蔽中断,intr_flag 置为 1
{
proc->pid = get_pid();
hash_proc(proc); //建立映射
nr_process ++; //进程数加1
list_add(&proc_list, &(proc->list_link));//将进程加入到进程的链表中
}
local_intr_restore(intr_flag);//恢复中断
//步骤七:唤醒子进程
wakeup_proc(proc);
//步骤八:返回子进程的pid
ret = proc->pid;
//下面的部分已经给出,不需要自己实现
fork_out:
return ret;
bad_fork_cleanup_kstack:
put_kstack(proc);
bad_fork_cleanup_proc:
kfree(proc);
goto fork_out;
}
问题回答
1. 请说明ucore是否做到给每个新fork的线程一个唯一的id?请说明你的分析和理由。
ucore中,每个新fork的线程都存在唯一的一个ID,理由如下:
-
在函数
get_pid中,如果静态成员last_pid小于next_safe,则当前分配的last_pid一定是安全的,即唯一的PID。 -
但如果
last_pid大于等于next_safe,或者last_pid的值超过MAX_PID,则当前的last_pid就不一定是唯一的PID,此时就需要遍历proc_list,重新对last_pid和next_safe进行设置,为下一次的get_pid调用打下基础。 -
之所以在该函数中维护一个合法的
PID的区间,是为了优化时间效率。如果简单的暴力搜索,则需要搜索大部分PID和所有的线程,这会使该算法的时间消耗很大,因此使用PID区间来优化算法。 -
get_pid代码如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
// get_pid - alloc a unique pid for process static int get_pid(void) { static_assert(MAX_PID > MAX_PROCESS); struct proc_struct *proc; list_entry_t *list = &proc_list, *le; static int next_safe = MAX_PID, last_pid = MAX_PID; if (++ last_pid >= MAX_PID) { last_pid = 1; goto inside; } if (last_pid >= next_safe) { inside: next_safe = MAX_PID; repeat: le = list; while ((le = list_next(le)) != list) { proc = le2proc(le, list_link); if (proc->pid == last_pid) { if (++ last_pid >= next_safe) { if (last_pid >= MAX_PID) last_pid = 1; next_safe = MAX_PID; goto repeat; } } else if (proc->pid > last_pid && next_safe > proc->pid) next_safe = proc->pid; } } return last_pid; }
练习3:阅读代码,理解 proc_run 函数和它调用的函数如何完成进程切换的
在实验报告中简要说明你对proc_run函数的分析。并回答如下问题:
- 在本实验的执行过程中,创建且运行了几个内核线程?
- 语句
local_intr_save(intr_flag);....local_intr_restore(intr_flag);在这里有何作用?请说明理由
完成代码编写后,编译并运行代码:make qemu
如果可以得到如 附录A所示的显示内容(仅供参考,不是标准答案输出),则基本正确。
实验执行流程概述
lab2和lab3完成了对内存的虚拟化,但整个控制流还是一条线串行执行。lab4将在此基础上进行CPU的虚拟化,即让ucore实现分时共享CPU,实现多条控制流能够并发执行。从某种程度上,我们可以把控制流看作是一个内核线程。本次实验将首先接触的是内核线程的管理。内核线程是一种特殊的进程,内核线程与用户进程的区别有两个:内核线程只运行在内核态而用户进程会在在用户态和内核态交替运行;所有内核线程直接使用共同的ucore内核内存空间,不需为每个内核线程维护单独的内存空间而用户进程需要维护各自的用户内存空间。从内存空间占用情况这个角度上看,我们可以把线程看作是一种共享内存空间的轻量级进程。
为了实现内核线程,需要设计管理线程的数据结构,即进程控制块(在这里也可叫做线程控制块)。如果要让内核线程运行,我们首先要创建内核线程对应的进程控制块,还需把这些进程控制块通过链表连在一起,便于随时进行插入,删除和查找操作等进程管理事务。这个链表就是进程控制块链表。然后在通过调度器(scheduler)来让不同的内核线程在不同的时间段占用CPU执行,实现对CPU的分时共享。那lab4中是如何一步一步实现这个过程的呢?
我们还是从lab4/kern/init/init.c中的kern_init函数入手分析。在kern_init函数中,当完成虚拟内存的初始化工作后,就调用了proc_init函数,这个函数完成了idleproc内核线程和initproc内核线程的创建或复制工作,这也是本次实验要完成的练习。idleproc内核线程的工作就是不停地查询,看是否有其他内核线程可以执行了,如果有,马上让调度器选择那个内核线程执行(请参考cpu_idle函数的实现)。所以idleproc内核线程是在ucore操作系统没有其他内核线程可执行的情况下才会被调用。接着就是调用kernel_thread函数来创建initproc内核线程。initproc内核线程的工作就是显示“Hello World”,表明自己存在且能正常工作了。
调度器会在特定的调度点上执行调度,完成进程切换。在lab4中,这个调度点就一处,即在cpu_idle函数中,此函数如果发现当前进程(也就是idleproc)的need_resched置为1(在初始化idleproc的进程控制块时就置为1了),则调用schedule函数,完成进程调度和进程切换。进程调度的过程其实比较简单,就是在进程控制块链表中查找到一个“合适”的内核线程,所谓“合适”就是指内核线程处于“PROC_RUNNABLE”状态。在接下来的switch_to函数(在后续有详细分析,有一定难度,需深入了解一下)完成具体的进程切换过程。一旦切换成功,那么initproc内核线程就可以通过显示字符串来表明本次实验成功。
接下来将主要介绍了进程创建所需的重要数据结构–进程控制块 proc_struct,以及ucore创建并执行内核线程idleproc和initproc的两种不同方式,特别是创建initproc的方式将被延续到实验五中,扩展为创建用户进程的主要方式。另外,还初步涉及了进程调度(实验六涉及并会扩展)和进程切换内容。
创建第 0 个内核线程 idleproc
在init.c::kern_init函数调用了proc.c::proc_init函数。proc_init函数启动了创建内核线程的步骤。首先当前的执行上下文(从kern_init 启动至今)就可以看成是uCore内核(也可看做是内核进程)中的一个内核线程的上下文。为此,uCore通过给当前执行的上下文分配一个进程控制块以及对它进行相应初始化,将其打造成第0个内核线程 – idleproc。具体步骤如下:
首先调用alloc_proc函数来通过kmalloc函数获得proc_struct结构的一块内存块-,作为第0个进程控制块。并把proc进行初步初始化(即把proc_struct中的各个成员变量清零)。但有些成员变量设置了特殊的值,比如:
1
2
3
4
proc->state = PROC_UNINIT; 设置进程为“初始”态
proc->pid = -1; 设置进程pid的未初始化值
proc->cr3 = boot_cr3; 使用内核页目录表的基址
...
上述三条语句中,第一条设置了进程的状态为“初始”态,这表示进程已经 “出生”了,正在获取资源茁壮成长中;第二条语句设置了进程的pid为-1,这表示进程的“身份证号”还没有办好;第三条语句表明由于该内核线程在内核中运行,故采用为uCore内核已经建立的页表,即设置为在uCore内核页表的起始地址boot_cr3。后续实验中可进一步看出所有内核线程的内核虚地址空间(也包括物理地址空间)是相同的。既然内核线程共用一个映射内核空间的页表,这表示内核空间对所有内核线程都是“可见”的,所以更精确地说,这些内核线程都应该是从属于同一个唯一的“大内核进程”—uCore内核。
接下来,proc_init函数对idleproc内核线程进行进一步初始化:
1
2
3
4
5
idleproc->pid = 0;
idleproc->state = PROC_RUNNABLE;
idleproc->kstack = (uintptr_t)bootstack;
idleproc->need_resched = 1;
set_proc_name(idleproc, "idle");
需要注意前4条语句。第一条语句给了idleproc合法的身份证号–0,这名正言顺地表明了idleproc是第0个内核线程。通常可以通过pid的赋值来表示线程的创建和身份确定。“0”是第一个的表示方法是计算机领域所特有的,比如C语言定义的第一个数组元素的小标也是“0”。第二条语句改变了idleproc的状态,使得它从“出生”转到了“准备工作”,就差uCore调度它执行了。第三条语句设置了idleproc所使用的内核栈的起始地址。需要注意以后的其他线程的内核栈都需要通过分配获得,因为uCore启动时设置的内核栈直接分配给idleproc使用了。第四条很重要,因为uCore希望当前CPU应该做更有用的工作,而不是运行idleproc这个“无所事事”的内核线程,所以把idleproc->need_resched设置为“1”,结合idleproc的执行主体–cpu_idle函数的实现,可以清楚看出如果当前idleproc在执行,则只要此标志为1,马上就调用schedule函数要求调度器切换其他进程执行。
创建第 1 个内核线程 initproc
第0个内核线程主要工作是完成内核中各个子系统的初始化,然后就通过执行cpu_idle函数开始过退休生活了。所以uCore接下来还需创建其他进程来完成各种工作,但idleproc内核子线程自己不想做,于是就通过调用kernel_thread函数创建了一个内核线程init_main。在实验四中,这个子内核线程的工作就是输出一些字符串,然后就返回了(参看init_main函数)。但在后续的实验中,init_main的工作就是创建特定的其他内核线程或用户进程(实验五涉及)。下面我们来分析一下创建内核线程的函数kernel_thread:
1
2
3
4
5
6
7
8
9
10
11
kernel_thread(int (*fn)(void *), void *arg, uint32_t clone_flags)
{
struct trapframe tf;
memset(&tf, 0, sizeof(struct trapframe));
tf.tf_cs = KERNEL_CS;
tf.tf_ds = tf_struct.tf_es = tf_struct.tf_ss = KERNEL_DS;
tf.tf_regs.reg_ebx = (uint32_t)fn;
tf.tf_regs.reg_edx = (uint32_t)arg;
tf.tf_eip = (uint32_t)kernel_thread_entry;
return do_fork(clone_flags | CLONE_VM, 0, &tf);
}
注意,kernel_thread函数采用了局部变量tf来放置保存内核线程的临时中断帧,并把中断帧的指针传递给do_fork函数,而do_fork函数会调用copy_thread函数来在新创建的进程内核栈上专门给进程的中断帧分配一块空间。
给中断帧分配完空间后,就需要构造新进程的中断帧,具体过程是:首先给tf进行清零初始化,并设置中断帧的代码段(tf.tf_cs)和数据段(tf.tf_ds/tf_es/tf_ss)为内核空间的段(KERNEL_CS/KERNEL_DS),这实际上也说明了initproc内核线程在内核空间中执行。而initproc内核线程从哪里开始执行呢?tf.tf_eip的指出了是kernel_thread_entry(位于kern/process/entry.S中),kernel_thread_entry是entry.S中实现的汇编函数,它做的事情很简单:
kernel_thread_entry: # void kernel_thread(void)
pushl %edx # push arg
call *%ebx # call fn
pushl %eax # save the return value of fn(arg)
call do_exit # call do_exit to terminate current thread
从上可以看出,kernel_thread_entry函数主要为内核线程的主体fn函数做了一个准备开始和结束运行的“壳”,并把函数fn的参数arg(保存在edx寄存器中)压栈,然后调用fn函数,把函数返回值eax寄存器内容压栈,调用do_exit函数退出线程执行。
do_fork是创建线程的主要函数。kernel_thread函数通过调用do_fork函数最终完成了内核线程的创建工作。下面我们来分析一下do_fork函数的实现(练习2)。do_fork函数主要做了以下6件事情:
- 分配并初始化进程控制块(alloc_proc函数);
- 分配并初始化内核栈(setup_stack函数);
- 根据clone_flag标志复制或共享进程内存管理结构(copy_mm函数);
- 设置进程在内核(将来也包括用户态)正常运行和调度所需的中断帧和执行上下文(copy_thread函数);
- 把设置好的进程控制块放入hash_list和proc_list两个全局进程链表中;
- 自此,进程已经准备好执行了,把进程状态设置为“就绪”态;
- 设置返回码为子进程的id号。
这里需要注意的是,如果上述前3步执行没有成功,则需要做对应的出错处理,把相关已经占有的内存释放掉。copy_mm函数目前只是把current->mm设置为NULL,这是由于目前在实验四中只能创建内核线程,proc->mm描述的是进程用户态空间的情况,所以目前mm还用不上。copy_thread函数做的事情比较多,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
static void
copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) {
//在内核堆栈的顶部设置中断帧大小的一块栈空间
proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1;
*(proc->tf) = *tf; //拷贝在kernel_thread函数建立的临时中断帧的初始值
proc->tf->tf_regs.reg_eax = 0;
//设置子进程/线程执行完do_fork后的返回值
proc->tf->tf_esp = esp; //设置中断帧中的栈指针esp
proc->tf->tf_eflags |= FL_IF; //使能中断
proc->context.eip = (uintptr_t)forkret;
proc->context.esp = (uintptr_t)(proc->tf);
}
此函数首先在内核堆栈的顶部设置中断帧大小的一块栈空间,并在此空间中拷贝在kernel_thread函数建立的临时中断帧的初始值,并进一步设置中断帧中的栈指针esp和标志寄存器eflags,特别是eflags设置了FL_IF标志,这表示此内核线程在执行过程中,能响应中断,打断当前的执行。执行到这步后,此进程的中断帧就建立好了,对于initproc而言,它的中断帧如下所示:
1
2
3
4
5
6
7
8
9
10
11
//所在地址位置
initproc->tf= (proc->kstack+KSTACKSIZE) – sizeof (struct trapframe);
//具体内容
initproc->tf.tf_cs = KERNEL_CS;
initproc->tf.tf_ds = initproc->tf.tf_es = initproc->tf.tf_ss = KERNEL_DS;
initproc->tf.tf_regs.reg_ebx = (uint32_t)init_main;
initproc->tf.tf_regs.reg_edx = (uint32_t) ADDRESS of "Helloworld!!";
initproc->tf.tf_eip = (uint32_t)kernel_thread_entry;
initproc->tf.tf_regs.reg_eax = 0;
initproc->tf.tf_esp = esp;
initproc->tf.tf_eflags |= FL_IF;
设置好中断帧后,最后就是设置initproc的进程上下文,(process context,也称执行现场)了。只有设置好执行现场后,一旦uCore调度器选择了initproc执行,就需要根据initproc->context中保存的执行现场来恢复initproc的执行。这里设置了initproc的执行现场中主要的两个信息:上次停止执行时的下一条指令地址context.eip和上次停止执行时的堆栈地址context.esp。其实initproc还没有执行过,所以这其实就是initproc实际执行的第一条指令地址和堆栈指针。可以看出,由于initproc的中断帧占用了实际给initproc分配的栈空间的顶部,所以initproc就只能把栈顶指针context.esp设置在initproc的中断帧的起始位置。根据context.eip的赋值,可以知道initproc实际开始执行的地方在forkret函数(主要完成do_fork函数返回的处理工作)处。至此,initproc内核线程已经做好准备执行了。
调度并执行内核线程 initproc
在uCore执行完proc_init函数后,就创建好了两个内核线程:idleproc和initproc,这时uCore当前的执行现场就是idleproc,等到执行到init函数的最后一个函数cpu_idle之前,uCore的所有初始化工作就结束了,idleproc将通过执行cpu_idle函数让出CPU,给其它内核线程执行,具体过程如下:
1
2
3
4
5
6
void
cpu_idle(void) {
while (1) {
if (current->need_resched) {
schedule();
……
首先,判断当前内核线程idleproc的need_resched是否不为0,回顾前面“创建第一个内核线程idleproc”中的描述,proc_init函数在初始化idleproc中,就把idleproc->need_resched置为1了,所以会马上调用schedule函数找其他处于“就绪”态的进程执行。
uCore在实验四中只实现了一个最简单的FIFO调度器,其核心就是schedule函数。它的执行逻辑很简单:
1.设置当前内核线程current->need_resched为0; 2.在proc_list队列中查找下一个处于“就绪”态的线程或进程next; 3.找到这样的进程后,就调用proc_run函数,保存当前进程current的执行现场(进程上下文),恢复新进程的执行现场,完成进程切换。
至此,新的进程next就开始执行了。由于在proc10中只有两个内核线程,且idleproc要让出CPU给initproc执行,我们可以看到schedule函数通过查找proc_list进程队列,只能找到一个处于“就绪”态的initproc内核线程。并通过proc_run和进一步的switch_to函数完成两个执行现场的切换,具体流程如下:
- 让current指向next内核线程initproc;
- 设置任务状态段ts中特权态0下的栈顶指针esp0为next内核线程initproc的内核栈的栈顶,即next->kstack + KSTACKSIZE ;
- 设置CR3寄存器的值为next内核线程initproc的页目录表起始地址next->cr3,这实际上是完成进程间的页表切换;
- 由switch_to函数完成具体的两个线程的执行现场切换,即切换各个寄存器,当switch_to函数执行完“ret”指令后,就切换到initproc执行了。
注意,在第二步设置任务状态段ts中特权态0下的栈顶指针esp0的目的是建立好内核线程或将来用户线程在执行特权态切换(从特权态0<–>特权态3,或从特权态3<–>特权态3)时能够正确定位处于特权态0时进程的内核栈的栈顶,而这个栈顶其实放了一个trapframe结构的内存空间。如果是在特权态3发生了中断/异常/系统调用,则CPU会从特权态3–>特权态0,且CPU从此栈顶(当前被打断进程的内核栈顶)开始压栈来保存被中断/异常/系统调用打断的用户态执行现场;如果是在特权态0发生了中断/异常/系统调用,则CPU会从从当前内核栈指针esp所指的位置开始压栈保存被中断/异常/系统调用打断的内核态执行现场。反之,当执行完对中断/异常/系统调用打断的处理后,最后会执行一个“iret”指令。在执行此指令之前,CPU的当前栈指针esp一定指向上次产生中断/异常/系统调用时CPU保存的被打断的指令地址CS和EIP,“iret”指令会根据ESP所指的保存的址CS和EIP恢复到上次被打断的地方继续执行。
在页表设置方面,由于idleproc和initproc都是共用一个内核页表boot_cr3,所以此时第三步其实没用,但考虑到以后的进程有各自的页表,其起始地址各不相同,只有完成页表切换,才能确保新的进程能够正常执行。
第四步proc_run函数调用switch_to函数,参数是前一个进程和后一个进程的执行现场:process context。在上一节“设计进程控制块”中,描述了context结构包含的要保存和恢复的寄存器。我们再看看switch.S中的switch_to函数的执行流程:
.globl switch_to
switch_to: # switch_to(from, to)
# save from's registers
movl 4(%esp), %eax # eax points to from
popl 0(%eax) # esp--> return address, so save return addr in FROM’s
context
movl %esp, 4(%eax)
……
movl %ebp, 28(%eax)
# restore to's registers
movl 4(%esp), %eax # not 8(%esp): popped return address already
# eax now points to to
movl 28(%eax), %ebp
……
movl 4(%eax), %esp
pushl 0(%eax) # push TO’s context’s eip, so return addr = TO’s eip
ret # after ret, eip= TO’s eip
首先,保存前一个进程的执行现场,前两条汇编指令(如下所示)保存了进程在返回switch_to函数后的指令地址到context.eip中
movl 4(%esp), %eax # eax points to from
popl 0(%eax) # esp--> return address, so save return addr in FROM’s
context
在接下来的7条汇编指令完成了保存前一个进程的其他7个寄存器到context中的相应成员变量中。至此前一个进程的执行现场保存完毕。再往后是恢复向一个进程的执行现场,这其实就是上述保存过程的逆执行过程,即从context的高地址的成员变量ebp开始,逐一把相关成员变量的值赋值给对应的寄存器,倒数第二条汇编指令“pushl 0(%eax)”其实把context中保存的下一个进程要执行的指令地址context.eip放到了堆栈顶,这样接下来执行最后一条指令“ret”时,会把栈顶的内容赋值给EIP寄存器,这样就切换到下一个进程执行了,即当前进程已经是下一个进程了。uCore会执行进程切换,让initproc执行。在对initproc进行初始化时,设置了initproc->context.eip = (uintptr_t)forkret,这样,当执行switch_to函数并返回后,initproc将执行其实际上的执行入口地址forkret。而forkret会调用位于kern/trap/trapentry.S中的forkrets函数执行,具体代码如下:
.globl __trapret
__trapret:
# restore registers from stack
popal
# restore %ds and %es
popl %es
popl %ds
# get rid of the trap number and error code
addl $0x8, %esp
iret
.globl forkrets
forkrets:
# set stack to this new process's trapframe
movl 4(%esp), %esp //把esp指向当前进程的中断帧
jmp __trapret
可以看出,forkrets函数首先把esp指向当前进程的中断帧,从_trapret开始执行到iret前,esp指向了current->tf.tf_eip,而如果此时执行的是initproc,则current->tf.tf_eip=kernel_thread_entry,initproc->tf.tf_cs = KERNEL_CS,所以当执行完iret后,就开始在内核中执行kernel_thread_entry函数了,而initproc->tf.tf_regs.reg_ebx = init_main,所以在kernl_thread_entry中执行“call %ebx”后,就开始执行initproc的主体了。Initprocde的主体函数很简单就是输出一段字符串,然后就返回到kernel_tread_entry函数,并进一步调用do_exit执行退出操作了。本来do_exit应该完成一些资源回收工作等,但这些不是实验四涉及的,而是由后续的实验来完成。至此,实验四中的主要工作描述完毕。
分析 proc_run 及其相关函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void
proc_run(struct proc_struct *proc) {
if (proc != current) {
bool intr_flag;
struct proc_struct *prev = current, *next = proc;
local_intr_save(intr_flag);
{
current = proc;
load_esp0(next->kstack + KSTACKSIZE);
lcr3(next->cr3);
switch_to(&(prev->context), &(next->context));
}
local_intr_restore(intr_flag);
}
}
proc_run 的作用是运行一个进程,如果要运行的进程和现在执行的一样,那就什么都不用做,否则的话,就把下一个要执行的进程的内核栈、页目录表加载进来,然后调用 switch_to 切换上下文。
switch_to 是一个汇编代码写的函数:
.text
.globl switch_to
switch_to: # switch_to(from, to)
# save from's registers
movl 4(%esp), %eax # eax points to from
popl 0(%eax) # save eip !popl
movl %esp, 4(%eax) # save esp::context of from
movl %ebx, 8(%eax) # save ebx::context of from
movl %ecx, 12(%eax) # save ecx::context of from
movl %edx, 16(%eax) # save edx::context of from
movl %esi, 20(%eax) # save esi::context of from
movl %edi, 24(%eax) # save edi::context of from
movl %ebp, 28(%eax) # save ebp::context of from
# restore to's registers
movl 4(%esp), %eax # not 8(%esp): popped return address already
# eax now points to to
movl 28(%eax), %ebp # restore ebp::context of to
movl 24(%eax), %edi # restore edi::context of to
movl 20(%eax), %esi # restore esi::context of to
movl 16(%eax), %edx # restore edx::context of to
movl 12(%eax), %ecx # restore ecx::context of to
movl 8(%eax), %ebx # restore ebx::context of to
movl 4(%eax), %esp # restore esp::context of to
pushl 0(%eax) # push eip
retCOPY
在调用这个函数的时候,栈的结构如下:
1
2
3
4
+| 栈底方向 | 高位地址
| to |
| from |
| 返回地址 | <-------- espCOPY
此时,from 在 esp + 4 处,存放指向 prev->context 的指针,然后按照 struct context 的结构依次保存现场,需要注意的是,在 popl 0(%eax) 之后,栈的结构变成了:
1
2
3
+| 栈底方向 | 高位地址
| to |
| from | <-------- espCOPY
所以,现在 esp + 4 处存放的就是 next->context 的指针了。此时读取 context 中的上下文,恢复进程的现场。
1
2
3
4
+| 栈底方向 | 高位地址
| to |
| from |
| 新进程 eip | <-------- espCOPY
最后,通过将 context 中的 eip 压栈,然后调用 ret 指令,使指令从新进程的现场继续执行。
在这次实验中,initproc 的 eip 在 copy_thread 中被设置成了 forkret:
1
2
3
4
5
6
7
8
9
10
11
static void
copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) {
proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1;
*(proc->tf) = *tf;
proc->tf->tf_regs.reg_eax = 0;
proc->tf->tf_esp = esp;
proc->tf->tf_eflags |= FL_IF;
proc->context.eip = (uintptr_t)forkret;
proc->context.esp = (uintptr_t)(proc->tf);
}
问题回答
1. 在本实验的执行过程中,创建且运行了几个内核线程?
-
在
proc_init中,只有两个内核线程被创建:idleproc和initproc:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
void proc_init(void) { int i; list_init(&proc_list); for (i = 0; i < HASH_LIST_SIZE; i ++) { list_init(hash_list + i); } if ((idleproc = alloc_proc()) == NULL) { panic("cannot alloc idleproc.\n"); } idleproc->pid = 0; idleproc->state = PROC_RUNNABLE; idleproc->kstack = (uintptr_t)bootstack; idleproc->need_resched = 1; set_proc_name(idleproc, "idle"); nr_process ++; current = idleproc; int pid = kernel_thread(init_main, "Hello world!!", 0); if (pid <= 0) { panic("create init_main failed.\n"); } initproc = find_proc(pid); set_proc_name(initproc, "init"); assert(idleproc != NULL && idleproc->pid == 0); assert(initproc != NULL && initproc->pid == 1); }
在其他初始化完成之后,ucore 就会调用
cpu_idle函数,这个函数是一个死循环,如果发现当前的内核线程让出了 CPU,就调用schedule函数进行进程调度。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
void schedule(void) { bool intr_flag; list_entry_t *le, *last; struct proc_struct *next = NULL; local_intr_save(intr_flag); { current->need_resched = 0; last = (current == idleproc) ? &proc_list : &(current->list_link); le = last; do { if ((le = list_next(le)) != &proc_list) { next = le2proc(le, list_link); if (next->state == PROC_RUNNABLE) { break; } } } while (le != last); if (next == NULL || next->state != PROC_RUNNABLE) { next = idleproc; } next->runs ++; if (next != current) { proc_run(next); } } local_intr_restore(intr_flag); }
在这次实验里,一开始是
idleproc在运行,而且自己的resched置位,所以调度器会马上被唤醒,调度到initproc中,而在kernel_thread函数中,设置了initproc运行的参数:1 2 3 4 5 6 7 8 9 10 11
int kernel_thread(int (*fn)(void *), void *arg, uint32_t clone_flags) { struct trapframe tf; memset(&tf, 0, sizeof(struct trapframe)); tf.tf_cs = KERNEL_CS; tf.tf_ds = tf.tf_es = tf.tf_ss = KERNEL_DS; tf.tf_regs.reg_ebx = (uint32_t)fn; tf.tf_regs.reg_edx = (uint32_t)arg; tf.tf_eip = (uint32_t)kernel_thread_entry; return do_fork(clone_flags | CLONE_VM, 0, &tf); }
initproc的中断栈帧的eip寄存器被设置成了kernel_thread_entry,ebx中保存着真正需要调用的函数地址,edx中保存着函数调用的参数。而在
do_fork的copy_thread函数中:1 2 3 4 5 6 7 8 9 10 11
static void copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) { proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1; *(proc->tf) = *tf; proc->tf->tf_regs.reg_eax = 0; proc->tf->tf_esp = esp; proc->tf->tf_eflags |= FL_IF; proc->context.eip = (uintptr_t)forkret; proc->context.esp = (uintptr_t)(proc->tf); }
可以看到内核线程的真正入口地址是
forkret,所以在switch_to调用之后,会跳转到forkret:1 2 3 4
static void forkret(void) { forkrets(current->tf); }
这是所有新进程的入口地址,
forkrets是汇编函数:.globl __trapret __trapret: # restore registers from stack popal # restore %ds, %es, %fs and %gs popl %gs popl %fs popl %es popl %ds # get rid of the trap number and error code addl $0x8, %esp iret .globl forkrets forkrets: # set stack to this new process's trapframe movl 4(%esp), %esp jmp __trapretCOPY这里简单地将之前设置的
trapframe的值写入到寄存器中,并调用iret返回(因为只有iret可以修改段寄存器的值),而此时就会进入kernel_thread_entry:.text .globl kernel_thread_entry kernel_thread_entry: # void kernel_thread(void) pushl %edx # push arg call *%ebx # call fn pushl %eax # save the return value of fn(arg) call do_exit # call do_exit to terminate current threadCOPY这里就是调用线程函数,
fn(arg),将返回值保存到栈上,最后调用do_exit退出进程:1 2 3 4
int do_exit(int error_code) { panic("process exit!!.\n"); }
实验执行到这里就结束了。
2. 语句local_intr_save(intr_flag);....local_intr_restore(intr_flag);在这里有何作用?请说明理由
- 这两句代码的作用分别是阻塞中断和解除中断的阻塞。
- 这两句的配合,使得这两句代码之间的代码块形成原子操作,可以使得某些关键的代码不会被打断,从而避免引起一些未预料到的错误,避免条件竞争。
- 以进程切换为例,在
proc_run中,当刚设置好current指针为下一个进程,但还未完全将控制权转移时,如果该过程突然被一个中断所打断,则中断处理例程的执行可能会引发异常,因为current指针指向的进程与实际使用的进程资源不一致。
检验
填写完代码后在终端输入 make qemu ,得到如下结果:
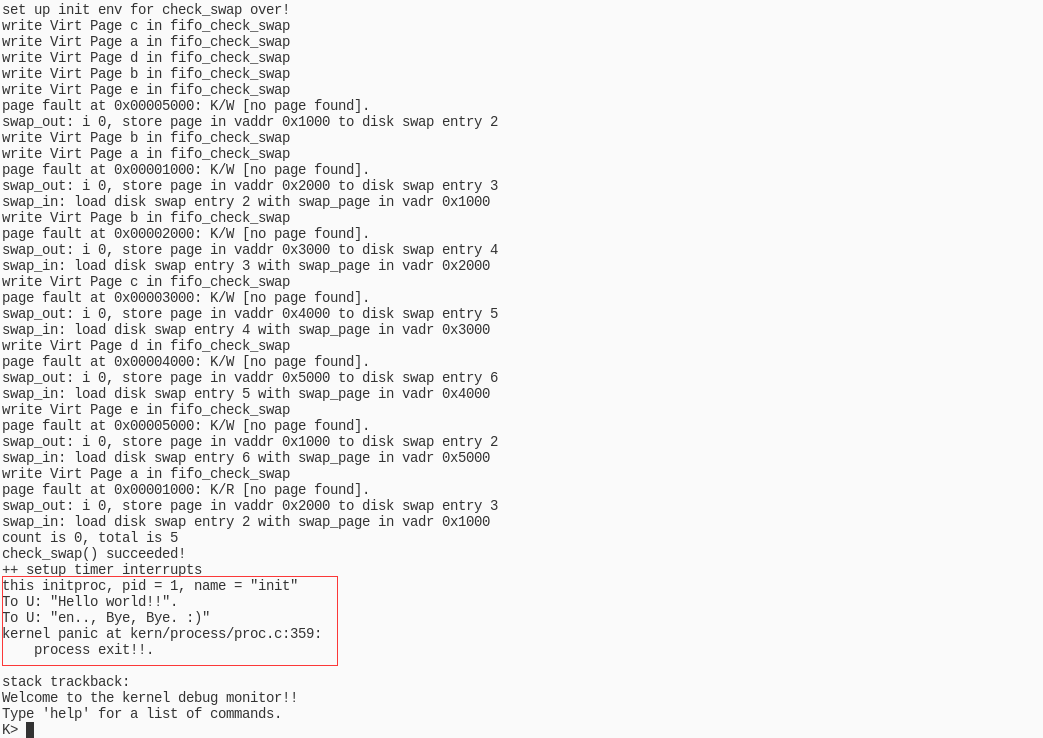
可以得到如附录A所示的显示内容,说明检验成功
再在终端输入 make grade 进行检验

可以看到得了满分,说明实验成功
扩展练习Challenge:实现支持任意大小的内存分配算法
这不是本实验的内容,其实是上一次实验内存的扩展,但考虑到现在的slab算法比较复杂,有必要实现一个比较简单的任意大小内存分配算法。可参考本实验中的slab如何调用基于页的内存分配算法(注意,不是要你关注slab的具体实现)来实现first-fit/best-fit/worst-fit/buddy等支持任意大小的内存分配算法。。
【注意】下面是相关的Linux实现文档,供参考
SLOB
http://en.wikipedia.org/wiki/SLOB http://lwn.net/Articles/157944/
SLAB
https://www.ibm.com/developerworks/cn/linux/l-linux-slab-allocator/
通过少量的修改,即可使用实验2扩展练习实现的 Slub 算法。
- 初始化 Slub 算法:在初始化物理内存最后初始化 Slub ;
1
2
3
4
void pmm_init(void) {
...
kmem_int();
}
- 在 vmm.c 中使用 Slub 算法:
为了使用Slub算法,需要声明仓库的指针。
1
2
struct kmem_cache_t *vma_cache = NULL;
struct kmem_cache_t *mm_cache = NULL;
在虚拟内存初始化时创建仓库。
1
2
3
4
5
void vmm_init(void) {
mm_cache = kmem_cache_create("mm", sizeof(struct mm_struct), NULL, NULL);
vma_cache = kmem_cache_create("vma", sizeof(struct vma_struct), NULL, NULL);
...
}
在 mm_create 和 vma_create 中使用 Slub 算法。
1
2
3
4
5
6
7
8
9
struct mm_struct *mm_create(void) {
struct mm_struct *mm = kmem_cache_alloc(mm_cache);
...
}
struct vma_struct *vma_create(uintptr_t vm_start, uintptr_t vm_end, uint32_t vm_flags) {
struct vma_struct *vma = kmem_cache_alloc(vma_cache);
...
}
在 mm_destroy 中释放内存。
1
2
3
4
5
6
7
8
9
10
void
mm_destroy(struct mm_struct *mm) {
...
while ((le = list_next(list)) != list) {
...
kmem_cache_free(mm_cache, le2vma(le, list_link)); //kfree vma
}
kmem_cache_free(mm_cache, mm); //kfree mm
...
}
- 在 proc.c 中使用 Slub 算法:
声明仓库指针。
1
struct kmem_cache_t *proc_cache = NULL;
在初始化函数中创建仓库。
1
2
3
4
5
void proc_init(void) {
...
proc_cache = kmem_cache_create("proc", sizeof(struct proc_struct), NULL, NULL);
...
}
在 alloc_proc 中使用 Slub 算法。
1
2
3
4
static struct proc_struct *alloc_proc(void) {
struct proc_struct *proc = kmem_cache_alloc(proc_cache);
...
}
本实验没有涉及进程结束后 PCB 回收,不需要回收内存。(借鉴自 AngelKitty )
重要知识点
1. 进程
1) 概念
- 进程是指一个具有一定独立功能的程序在一个数据集合上的一次动态执行过程,其中包括正在运行的一个程序的所有状态信息。
- 进程是程序的执行,有核心态/用户态,是一个状态变化的过程
- 进程的组成包括程序、数据块和进程控制块PCB。
2) 进程控制块
进程控制块,Process Control Block, PCB。
- 进程控制块是操作系统管理控制进程运行所用的信息集合。操作系统用PCB来描述进程的基本情况以及运行变化的过程。
- PCB是进程存在的唯一标志 ,每个进程都在操作系统中有一个对应的PCB。
- 进程控制块可以通过某个数据结构组织起来(例如链表)。同一状态进程的PCB连接成一个链表,多个状态对应多个不同的链表。各状态的进程形成不同的链表:就绪联链表,阻塞链表等等。
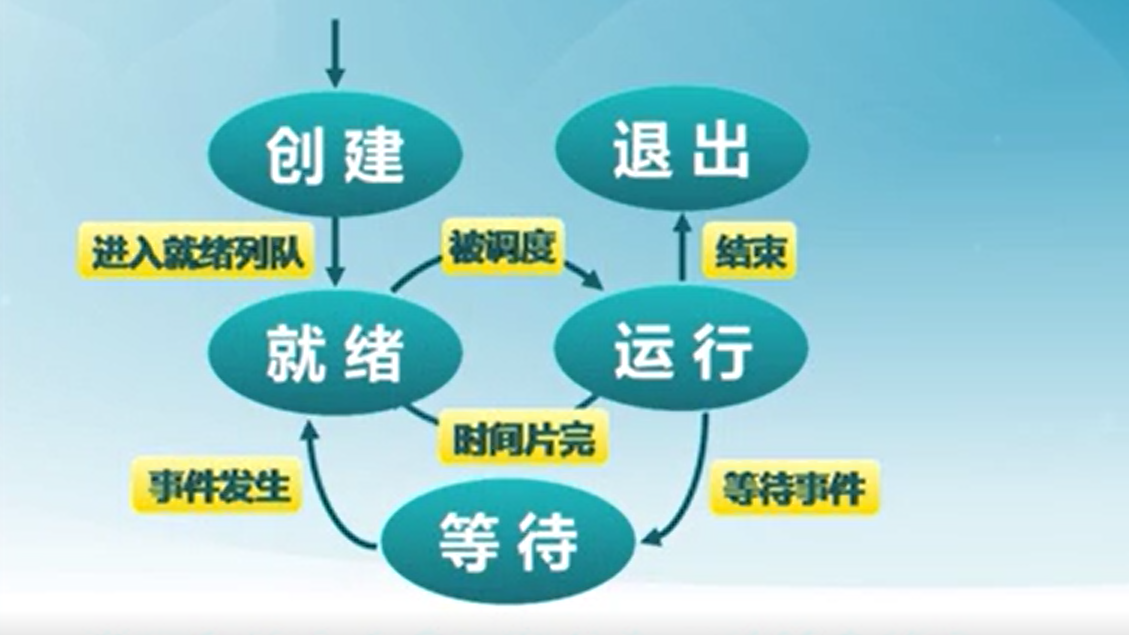
3) 进程状态
进程的生命周期通常有6种情况:进程创建、进程执行、进程等待、进程抢占、进程唤醒、进程结束。
部分周期没有在图中标注。
-
引起进程创建的情况:
- 系统初始化,创建idle进程。
- 用户或正在运行的进程请求创建新进程。
-
进程等待(阻塞)的情况:
- 进程请求并等待某个系统服务,无法马上完成。
- 启动某种操作,无法马上完成。
- 需要的数据没有到达。
只有该进程本身才能让自己进入休眠,但只有外部(例如操作系统)才能将该休眠的进程唤醒。
-
引起进程被抢占的情况
- 高优先级进程就绪
- 进程执行当前时间用完(时间片耗尽)
-
唤醒进程的情况:
- 被阻塞进程需要的资源可被满足。
- 被阻塞进程等待的事件到达。
进程只能被别的进程或操作系统唤醒。
-
进程结束的情况
- 正常或异常退出(自愿)
- 致命错误(强制性,例如SIGSEV)
- 被其他进程所
kill(强制)
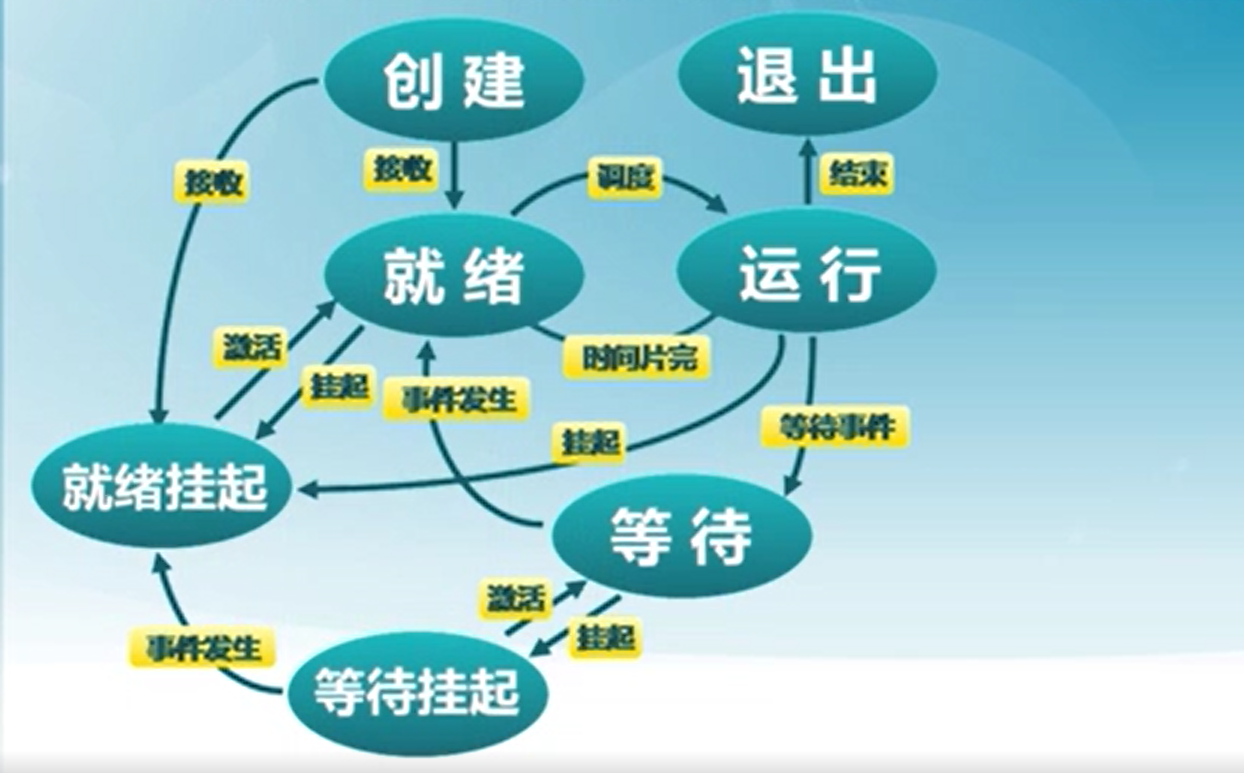
4) 进程挂起
将处于挂起状态的进程映像在磁盘上,目的是减少进程占用的内存。
其模型图如下
 以下是状态切换的简单介绍
以下是状态切换的简单介绍
- 等待挂起(Blocked-suspend): 进程在外存并等待某事件的出现。
- 就绪挂起(Ready-suspend):进程在外存,但只要进入内存,即可运行。
- 挂起(Suspend):把一个进程从内存转到外存。
- 等待到等待挂起:没有进程处于就绪状态或就绪进程要求更多内存资源。
- 就绪到就绪挂起:当有高优先级进程处于等待状态(系统认为很快会就绪的),低优先级就绪进程会挂起,为高优先级进程提供更大的内存空间。
- 运行到就绪挂起:当有高优先级等待进程因事件出现而进入就绪挂起。
- 等待挂起到就绪挂起:当有等待挂起进程因相关事件出现而转换状态。
- 激活(Activate):把一个进程从外存转到内存
- 就绪挂起到就绪:没有就绪进程或挂起就绪进程优先级高于就绪进程。
- 等待挂起到等待:当一个进程释放足够内存,并有高优先级等待挂起进程。
2. 线程
1) 概念
线程是进程的一部分,描述指令流执行状态,是进程中的指令执行流最小单位,是CPU调度的基本单位。
进程的资源分配角色:进程由一组相关资源构成,包括地址空间、打开的文件等各种资源。
线程的处理机调度角色:线程描述在进程资源环境中指令流执行状态。
2) 优缺点
- 优点:
- 一个进程中可以存在多个线程
- 各个线程可以并发执行
- 各个线程之间可以共享地址空间和文件等资源。
- 缺点:
- 一个线程崩溃,会导致其所属的进程的所有线程崩溃。
3) 用户线程与内核线程
线程有三种实现方式
- 用户线程:在用户空间实现。(POSIX Pthread)
- 内核线程:在内核中实现。(Windows, Linux)
- 轻权进程:在内核中实现,支持用户线程。
a. 用户线程
用户线程是由一组用户级的线程库函数来完成线程的管理,包括线程的创建、终止、同步和调度等。
- 用户线程的特征
- 不依赖于操作系统内核,在用户空间实现线程机制。
- 可用于不支持线程的多进程操作系统。
- 线程控制模块(TCB)由线程库函数内部维护。
- 同一个进程内的用户线程切换速度块,无需用户态/核心态切换。
- 允许每个进程拥有自己的线程调度算法。
- 不依赖于操作系统内核,在用户空间实现线程机制。
- 用户进程的缺点
- 线程发起系统调用而阻塞时,整个进程都会进入等待状态。
- 不支持基于线程的处理机抢占。
- 只能按进程分配CPU时间。
b. 内核线程
内核线程是由内核通过系统调用实现的线程机制,由内核完成线程的创建、终止和管理。
内核线程的特征
- 由内核自己维护PCB和TCB
- 线程执行系统调用而被阻塞不影响其他线程。
- 线程的创建、终止和切换消耗相对较大。
- 以线程为单位进行CPU时间分配。其中多线程进程可以获得更多的CPU时间。
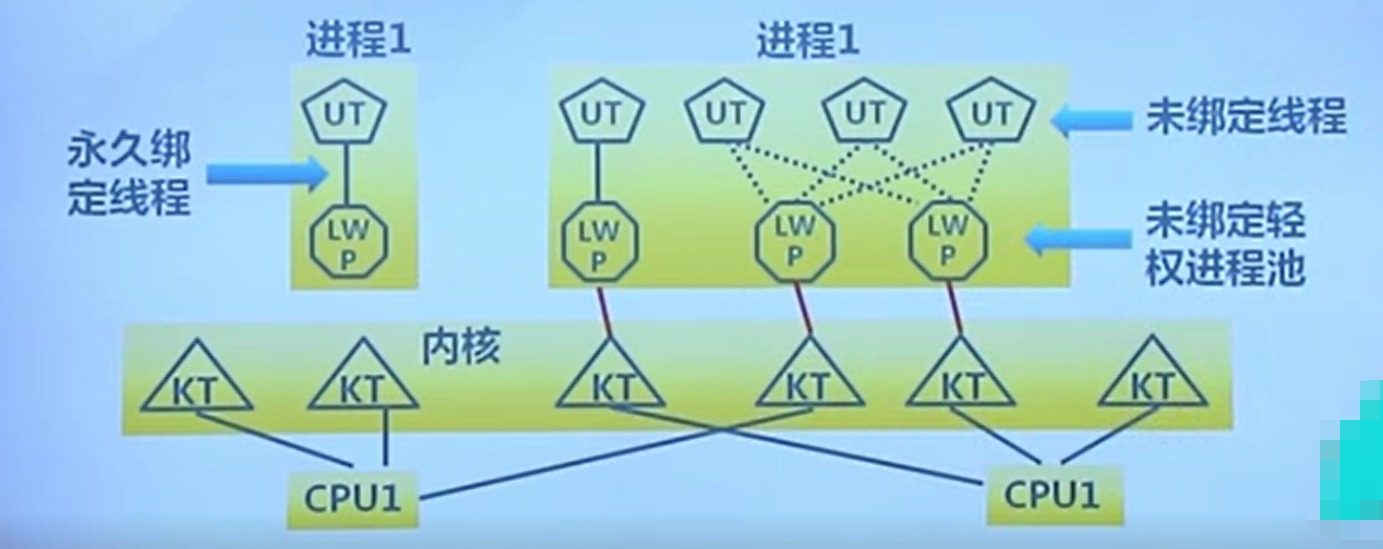
c. 轻权进程
用户线程可以自定义调度算法,但存在部分缺点。而内核线程不存在用户线程的各种缺点。
所以轻权进程是用户线程与内核线程的结合产物。
-
内核支持的用户线程。一个进程可包含一个或多个轻权进程,每个轻权进程由一个单独的内核线程来支持。
-
过于复杂以至于优点没有体现出来,最后演化为单一的内核线程支持。以下是其模型图:
3. 线程与进程的比较
- 进程是资源分配单元,而线程是CPU调度单位。
- 进程拥有一个完整的资源平台,而线程只独享指令流执行的必要资源,例如寄存器与栈。
- 线程具有就绪、等待和运行三种基本状态和状态间的转换关系。
- 线程能减小并发执行的事件和空闲开销。
- 线程的创建时间和终止时间比进程短。
- 同一进程内的线程切换时间比进程短。
- 由于同一进程的各线程间共享内存和文件资源,可不通过内核进行直接通信。
4. 进程控制
1) 进程切换
a. 过程
- 暂停当前进程,保存上下文,并从运行状态变成其他状态。
- 最后调度另一个进程,恢复其上下文并从就绪状态转为运行状态。
进程切换的要求:速度要快。
b. 进程控制块PCB
进程切换涉及到进程控制块PCB结构.
-
内核为每个进程维护了对应的进程控制块(PCB)
-
内核将相同状态的进程的PCB放置在同一队列里。
-
其中,uCore中PCB结构如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
enum proc_state { PROC_UNINIT = 0, // 未初始化的 -- alloc_proc PROC_SLEEPING, // 等待状态 -- try_free_pages, do_wait, do_sleep PROC_RUNNABLE, // 就绪/运行状态 -- proc_init, wakeup_proc, PROC_ZOMBIE, // 僵死状态 -- do_exit }; struct context { // 保存的上下文寄存器,注意没有eax寄存器和段寄存器 uint32_t eip; uint32_t esp; uint32_t ebx; uint32_t ecx; uint32_t edx; uint32_t esi; uint32_t edi; uint32_t ebp; }; struct proc_struct { enum proc_state state; // 当前进程的状态 int pid; // 进程ID int runs; // 当前进程被调度的次数 uintptr_t kstack; // 内核栈 volatile bool need_resched; // 是否需要被调度 struct proc_struct *parent; // 父进程ID struct mm_struct *mm; // 当前进程所管理的虚拟内存页,包括其所属的页目录项PDT struct context context; // 保存的上下文 struct trapframe *tf; // 中断所保存的上下文 uintptr_t cr3; // 页目录表的地址 uint32_t flags; // 当前进程的相关标志 char name[PROC_NAME_LEN + 1]; // 进程名称(可执行文件名) list_entry_t list_link; // 用于连接list list_entry_t hash_link; // 用于连接hash list };
由于进程数量可能较大,倘若从头向后遍历查找符合某个状态的PCB,则效率会十分低下,因此使用了哈希表作为遍历所用的数据结构。
c. 切换流程
-
uCore中,内核的第一个进程
idleproc会执行cpu_idle函数,并从中调用schedule函数,准备开始调度进程。1 2 3 4 5
void cpu_idle(void) { while (1) if (current->need_resched)c schedule(); }
-
schedule函数会先清除调度标志,并从当前进程在链表中的位置开始,遍历进程控制块,直到找出处于就绪状态的进程。之后执行
proc_run函数,将环境切换至该进程的上下文并继续执行。需要注意的是,这个进程调度过程中不能被CPU中断给打断,原因是这可能造成条件竞争。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
void schedule(void) { bool intr_flag; list_entry_t *le, *last; struct proc_struct *next = NULL; local_intr_save(intr_flag); { current->need_resched = 0; last = (current == idleproc) ? &proc_list : &(current->list_link); le = last; do { if ((le = list_next(le)) != &proc_list) { next = le2proc(le, list_link); if (next->state == PROC_RUNNABLE) break; } } while (le != last); if (next == NULL || next->state != PROC_RUNNABLE) next = idleproc; next->runs ++; if (next != current) proc_run(next); } local_intr_restore(intr_flag); }
-
proc_run函数会设置TSS中ring0的内核栈地址,同时还会加载页目录表的地址。等到这些前置操作完成后,最后执行上下文切换。同样,设置内核栈地址与加载页目录项等这类关键操作不能被中断给打断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
void proc_run(struct proc_struct *proc) { if (proc != current) { bool intr_flag; struct proc_struct *prev = current, *next = proc; local_intr_save(intr_flag); { // 设置当前执行的进程 current = proc; // 设置ring0的内核栈地址 load_esp0(next->kstack + KSTACKSIZE); // 加载页目录表 lcr3(next->cr3); // 切换上下文 switch_to(&(prev->context), &(next->context)); } local_intr_restore(intr_flag); } }
-
切换上下文的操作基本上都是直接与寄存器打交道,所以
switch_to函数使用汇编代码编写,详细信息以注释的形式写入代码中。.text .globl switch_to switch_to: # switch_to(from, to) # save from's registers movl 4(%esp), %eax # 获取当前进程的context结构地址 popl 0(%eax) # 将eip保存至当前进程的context结构 movl %esp, 4(%eax) # 将esp保存至当前进程的context结构 movl %ebx, 8(%eax) # 将ebx保存至当前进程的context结构 movl %ecx, 12(%eax) # 将ecx保存至当前进程的context结构 movl %edx, 16(%eax) # 将edx保存至当前进程的context结构 movl %esi, 20(%eax) # 将esi保存至当前进程的context结构 movl %edi, 24(%eax) # 将edi保存至当前进程的context结构 movl %ebp, 28(%eax) # 将ebp保存至当前进程的context结构 # restore to's registers movl 4(%esp), %eax # 获取下一个进程的context结构地址 # 需要注意的是,其地址不是8(%esp),因为之前已经pop过一次栈。 movl 28(%eax), %ebp # 恢复ebp至下一个进程的context结构 movl 24(%eax), %edi # 恢复edi至下一个进程的context结构 movl 20(%eax), %esi # 恢复esi至下一个进程的context结构 movl 16(%eax), %edx # 恢复edx至下一个进程的context结构 movl 12(%eax), %ecx # 恢复ecx至下一个进程的context结构 movl 8(%eax), %ebx # 恢复ebx至下一个进程的context结构 movl 4(%eax), %esp # 恢复esp至下一个进程的context结构 pushl 0(%eax) # 插入下一个进程的eip,以便于ret到下个进程的代码位置。 ret
2) 进程创建
-
在Unix中,进程通过系统调用
fork和exec来创建一个进程。- 其中,
fork把一个进程复制成两个除PID以外完全相同的进程。 exec用新进程来重写当前进程,PID没有改变。
- 其中,
-
fork创建一个继承的子进程。该子进程复制父进程的所有变量和内存,以及父进程的所有CPU寄存器(除了某个特殊寄存器,以区分是子进程还是父进程)。 -
fork函数一次调用,返回两个值。父进程中返回子进程的PID,子进程中返回0。 -
fork函数的开销十分昂贵,其实现开销来源于- 对子进程分配内存。
- 复制父进程的内存和寄存器到子进程中。
而且,在大多数情况下,调用
fork函数后就紧接着调用exec,此时fork中的内存复制操作是无用的。因此,fork函数中使用写时复制技术(Copy on Write, COW)。
a. 空闲进程的创建
-
空闲进程主要工作是完成内核中各个子系统的初始化,并最后用于调度其他进程。该进程最终会一直在
cpu_idle函数中判断当前是否可调度。 -
由于该进程是为了调度进程而创建的,所以其
need_resched成员初始时为1。 -
uCore创建该空闲进程的源代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// 分配一个proc_struct结构 if ((idleproc = alloc_proc()) == NULL) panic("cannot alloc idleproc.\n"); // 该空闲进程作为第一个进程,pid为0 idleproc->pid = 0; // 设置该空闲进程始终可运行 idleproc->state = PROC_RUNNABLE; // 设置空闲进程的内核栈 idleproc->kstack = (uintptr_t)bootstack; // 设置该空闲进程为可调度 idleproc->need_resched = 1; set_proc_name(idleproc, "idle"); nr_process++; // 设置当前运行的进程为该空闲进程 current = idleproc;
b. 第一个内核进程的创建
-
第一个内核进程是未来所有新进程的父进程或祖先进程。
-
uCore创建第一个内核进程的代码如下
// 创建init的主线程 int pid = kernel_thread(init_main, "Hello world!!", 0); if (pid <= 0) { panic("create init_main failed.\n"); } // 通过pid 查找proc_struct initproc = find_proc(pid); set_proc_name(initproc, "init"); -
在
kernel_thread中,程序先设置trapframe结构,最后调用do_fork函数。注意该trapframe部分寄存器ebx、edx、eip被分别设置为目标函数地址、参数地址以及kernel_thread_entry地址(稍后会讲)。int kernel_thread(int (*fn)(void *), void *arg, uint32_t clone_flags) { struct trapframe tf; memset(&tf, 0, sizeof(struct trapframe)); tf.tf_cs = KERNEL_CS; tf.tf_ds = tf.tf_es = tf.tf_ss = KERNEL_DS; // ebx = fn tf.tf_regs.reg_ebx = (uint32_t)fn; // edx = arg tf.tf_regs.reg_edx = (uint32_t)arg; // eip = kernel_thread_entry tf.tf_eip = (uint32_t)kernel_thread_entry; return do_fork(clone_flags | CLONE_VM, 0, &tf); } -
do_fork函数会执行以下操作- 分配新进程的PCB,并设置PCB相关成员,包括父进程PCB地址,新内核栈地址,新PID等等。
- 复制/共享当前进程的所有内存空间到子进程里。
- 复制当前线程的上下文状态至子进程中。
- 将子进程PCB分别插入至普通双向链表与哈希表中,设置该子进程为可执行,并最终返回该子进程的PID。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
int do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf) { int ret = -E_NO_FREE_PROC; struct proc_struct *proc; if (nr_process >= MAX_PROCESS) goto fork_out; ret = -E_NO_MEM; // 首先分配一个PCB if ((proc = alloc_proc()) == NULL) goto fork_out; // fork肯定存在父进程,所以设置子进程的父进程 proc->parent = current; // 分配内核栈 if (setup_kstack(proc) != 0) goto bad_fork_cleanup_proc; // 将所有虚拟页数据复制过去 if (copy_mm(clone_flags, proc) != 0) goto bad_fork_cleanup_kstack; // 复制线程的状态,包括寄存器上下文等等 copy_thread(proc, stack, tf); // 将子进程的PCB添加进hash list或者list // 需要注意的是,不能让中断处理程序打断这一步操作 bool intr_flag; local_intr_save(intr_flag); { proc->pid = get_pid(); hash_proc(proc); list_add(&proc_list, &(proc->list_link)); nr_process ++; } local_intr_restore(intr_flag); // 设置新的子进程可执行 wakeup_proc(proc); // 返回子进程的pid ret = proc->pid; fork_out: return ret; bad_fork_cleanup_kstack: put_kstack(proc); bad_fork_cleanup_proc: kfree(proc); goto fork_out; }
-
do_fork函数中的copy_thread函数会执行以下操作-
将
kernel_thread中创建的新trapframe内容复制到该proc的tf成员中,并压入该进程自身的内核栈。 -
设置
trapframe的eax寄存器值为0,esp寄存器值为传入的esp,以及eflags加上中断标志位。设置eax寄存器的值为0,是因为子进程的fork函数返回的值为0。
-
最后,设置子进程上下文的
eip为forkret,esp为该trapframe的地址。
1 2 3 4 5 6 7 8 9 10 11
static void copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) { proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1; *(proc->tf) = *tf; proc->tf->tf_regs.reg_eax = 0; proc->tf->tf_esp = esp; proc->tf->tf_eflags |= FL_IF; proc->context.eip = (uintptr_t)forkret; proc->context.esp = (uintptr_t)(proc->tf); }
-
-
当该子进程被调度运行,上下文切换后(即此时current为该子进程的PCB地址),子进程会跳转至
forkret,而该函数是forkrets的一个wrapper。1 2 3
static void forkret(void) { forkrets(current->tf); }
forkrets是干什么用的呢?从current->tf中恢复上下文,跳转至current->tf->tf_eip,也就是kernel_thread_entry。# return falls through to trapret... .globl __trapret __trapret: # restore registers from stack popal # restore %ds, %es, %fs and %gs popl %gs popl %fs popl %es popl %ds # get rid of the trap number and error code addl $0x8, %esp iret .globl forkrets forkrets: # set stack to this new process's trapframe movl 4(%esp), %esp jmp __trapret -
kernel_thread_entry的代码非常简单,压入%edx寄存器的值作为参数,并调用%ebx寄存器所指向的代码,最后保存调用的函数的返回值,并do_exit。以
initproc为例,该函数此时的%edx即"Hello world!!"字符串的地址,%ebx即init_main函数的地址。.text. .globl kernel_thread_entry kernel_thread_entry: # void kernel_thread(void) pushl %edx # push arg call *%ebx # call fn pushl %eax # save the return value of fn(arg) call do_exit # call do_exit to terminate current threadkernel_thread函数设置控制流起始地址为kernel_thread_entry的目的,是想让一个内核进程在执行完函数后能够自动调用do_exit回收资源。
3) 进程终止
这里只简单介绍进程的有序终止。
-
进程结束时调用
exit(),完成进程资源回收。 -
1
exit函数调用的功能
- 将调用参数作为进程的“结果”
- 关闭所有打开的文件等占用资源。
- 释放内存
- 释放大部分进程相关的内核数据结构
- 检查父进程是否存活
- 如果存活,则保留结果的值,直到父进程使用。同时当前进程进入僵尸(zombie)状态。
- 如果没有,它将释放所有的数据结构,进程结束。
- 清理所有等待的僵尸进程。
- 进程终止是最终的垃圾收集(资源回收)。
实验中涉及的知识点列举
- OS中的进程、线程的创建
- OS中的进程、线程的管理
- OS中的进程、线程的调度过程
实验中未涉及的知识点列举
实验中未涉及的知识点包括:
- 虚拟内存管理,包括在物理内存不足的情况下将暂时使用不到的物理页换出到外存中,从而实现大于物理内存空间的虚拟内存空间;
- PageFault的处理;
- OS中进程间的同步互斥;
- OS中用于访问外存的文件系统;
- OS对IO设备的管理;
- 从内核态跳转到用户态的方式;
实验心得
从这次实验中,我对物理内存管理有了一个更好的理解,我们都知道 Linux 操作系统创始人 Linus 曾经说过
Talk is cheap. Show me the code.
我可以说,如果仅仅只是从课本上学理论知识,会做一些题,应付一下考试,这是完全没有什么问题的,你的成绩肯定不会差,但是我想问,这又能学到多少呢?让你自己写一些简单的代码都不会,最多也就只能纸上谈兵罢了
ucore 真的是一个很好地帮助我们理解操作系统的实验,让我们在自己实现动手的时候去理解操作系统,通过做实验指导书上的练习来一步步完善 ucore 操作系统,在这个过程中学习相关知识
在这次 lab4 中,我对内核线程管理有了一个更好的理解,在教材中虽然也有说到进程的管理,但是并没有提到内核进程线程的上下文切换,虽然这两者都差不多,但是还是有区别的
内核线程,它通常只是内核中的一小段代码或者函数,没有自己的“专属”空间。这是由于在uCore OS启动后,已经对整个内核内存空间进行了管理,通过设置页表建立了内核虚拟空间(即boot_cr3指向的二级页表描述的空间)。所以uCore OS内核中的所有线程都不需要再建立各自的页表,只需共享这个内核虚拟空间就可以访问整个物理内存了。从这个角度看,内核线程被uCore OS内核这个大“内核进程”所管理。
在练习一中,我更加清楚了 PCB 的具体结构,虽然这点教材也有说,但是基本上只是说了大概有什么东西,但是通过 ucore 中定义的数据结构我们可以很明显的看到一个进程里面需要包含的东西有哪些,并且也更加熟悉了中断帧里面的内容,并且也对上下文切换和中断处理过程更加了解了
在练习二中完成对 do_fork( ) 函数的填写的过程中,我更加清楚了 fork 的整个过程,并且也知道了哪些东西要一一复制过来,相比教材上笼统的说的复制,通过 ucore 实验确实让我的印象深刻了不少。并且我知道了在部分关键代码(不能在执行时中断),我们先要阻塞中断,等关键代码执行完再解除中断的阻塞。这两句的配合,使得这两句代码之间的代码块形成原子操作,可以使得某些关键的代码不会被打断,从而避免引起一些未预料到的错误,避免条件竞争。
在练习三中,通过对 proc_run() 及其相关函数的分析,我知道了一个进程/线程运行的大致过程,教材其实是没有这方面的内容的,教材中只有说到进程的切换和调度,但是没有提到有一个专门负责调度的内核线程
首先生成一个内核线程,这个线程就是用来寻找有没有就绪的进程/线程(也就是说这个线程专门用来调度),找到一个就绪的进程/线程,运行这个进程/线程,所以发生上下文切换,等这个进程/线程再次发生中断就有运行那个用来调度的内核线程,重复这个过程
参考资料
- https://chyyuu.gitbooks.io/ucore_os_docs/content/lab4/lab4_5_appendix_a.html
- https://blog.csdn.net/yyd19981117/article/details/86693130?ops_request_misc=&request_id=&biz_id=102&utm_term=ucore%E5%AE%9E%E9%AA%8C%E5%9B%9B&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-86693130.pc_search_es_clickV2&spm=1018.2226.3001.4187
- https://howardlau.me/university/ucore/ucore-os-lab-4.html
- https://github.com/AngelKitty/review_the_national_post-graduate_entrance_examination/blob/master/books_and_notes/professional_courses/operating_system/sources/ucore_os_lab/docs/lab_report/lab4/lab4%20%E5%AE%9E%E9%AA%8C%E6%8A%A5%E5%91%8A.md
- https://github.com/DelinQu/myCore/tree/master/4
- https://kiprey.github.io/2020/08/uCore-4