实验题目
ucore lab2 物理内存管理
实验目的
操作系统是一个软件,也需要通过某种机制加载并运行它。在这里我们将通过另外一个更加简单的软件-bootloader来完成这些工作。为此,我们需要完成一个能够切换到x86的保护模式并显示字符的bootloader,为启动操作系统ucore做准备。lab1提供了一个非常小的bootloader和ucore OS,整个bootloader执行代码小于512个字节,这样才能放到硬盘的主引导扇区中。通过分析和实现这个bootloader和ucore OS,读者可以了解到:
- 计算机原理
- CPU的编址与寻址: 基于分段机制的内存管理
- CPU的中断机制
- 外设:串口/并口/CGA,时钟,硬盘
- Bootloader软件
- 编译运行bootloader的过程
- 调试bootloader的方法
- PC启动bootloader的过程
- ELF执行文件的格式和加载
- 外设访问:读硬盘,在CGA上显示字符串
- ucore OS软件
- 编译运行ucore OS的过程
- ucore OS的启动过程
- 调试ucore OS的方法
- 函数调用关系:在汇编级了解函数调用栈的结构和处理过程
- 中断管理:与软件相关的中断处理
- 外设管理:时钟
实验内容
-
了解如何发现系统中的物理内存
-
了解如何建立对物理内 存的初步管理,即了解连续物理内存管理
-
了解页表相关的操作,即如何建立页表来实现虚拟内存到物理内存之间的映射,对段页式内存管理机制有一个比较全面的了解
练习0:填写已有实验
本实验依赖实验 1。可采用 diff 和 patch 工具进行半自动的合并( merge ),也可用一些图形化的比较 /merge 工具来手动合并,比如 meld,eclipse 中的 diff/merge 工具,understand 中的 diff/merge 工具 等。
我是用 meld 手动合并的,其实也就那几个填空的函数合一下,自己复制粘贴也是一模一样的
把 LAB1 的自己修改的三个 .c 文件 copy 到 LAB2 即可
1
2
3
kdebug.c
init.c
trap.c
以 kdebug.c 为例
执行命令:
1
meld
选择要比较的两个文件
点击绿色部分的箭头即可
练习1:实现 first-fit 连续物理内存分配算法
first fit算法原理
first fit 首次匹配算法原理内存分配算法上很简单 , 在教材中有介绍:
- 处理空闲内存管理的时候, 物理内存页管理器顺着双向链表进行搜索空闲内存区域,直到找到一个足够大的空闲区域,它尽可能少地搜索链表。如果空闲区域的大小和申请分配的大小正好一样,则把这个空闲区域分配出去,成功返回;否则将该空闲区分为两部分,一部分区域与申请分配的大小相等,把它分配出去,剩下的一部分区域形成新的空闲区。其释放内存的设计思路很简单,只需把这区域重新放回双向链表中即可
- first_fit 分配算法需要维护一个查找有序(地址按从小到大排列)空闲块(以页为最小单位的连续地址空间)的数据结构,双向链表是一个很好的选择。
- 首次匹配有速度优势(不需要遍历所有空闲块),但有时会让空闲列表开头的部分有很多碎片
关键数据结构和变量
管理连续空闲内存空间块的数据结构 free_area_t
为了有效地管理小连续内存空闲块。所有的连续内存空闲块可用一个双向链表管理起来,便于分配和释放,为此定义了一个free_area_t数据结构,包含了一个list_entry结构的双向链表指针和记录当前空闲页的个数的无符号整型变量nr_free。其中的链表指针指向了空闲的物理页。
1
2
3
4
typedef struct {
list_entry_t free_list; // 双向链表指针
unsigned int nr_free; // 记录当前空闲页的个数的无符号整型变量nr_free
} free_area_t;
成员变量:
- list_entry_t free_list: 双向链表指针
- unsigned int nr_free: 记录当前空闲页的个数的无符号整型变量nr_free
在 default_pmm.c 中定义了全局变量, 他们是 free_area_t 的数据成员:
1
2
#define free_list (free_area.free_list) //the list header 空闲块双向链表的头
#define nr_free (free_area.nr_free) //of free pages in this free list 空闲块的总数(以页为单位)
物理页数据结构 Page
为了与以后的分页机制配合,我们首先需要建立对整个计算机的每一个物理页的属性用结构Page来表示,它包含了映射此物理页的虚拟页个数,描述物理页属性的flags和双向链接各个Page结构的page_link双向链表。物理页数据结构Page在./kern/mm/memlayout.h中定义.
1
2
3
4
5
6
struct Page {
int ref; // 这页被页表的引用记数
uint32_t flags; // 此物理页的状态标记
unsigned int property; // 空闲块的数量c
list_entry_t page_link; // 链接比它地址小和大的其他连续内存空闲块
};
成员变量:
ref表示这样页被页表的引用记数,应该就是映射此物理页的虚拟页个数。一旦某页表中有一个页表项设置了虚拟页到这个 Page 管理的物理页的映射关系,就会把 Page 的 ref 加一。反之,若是解除,那就减一。flags表示此物理页的状态标记,有两个标志位,第一个表示是否被保留,如果被保留了则设为1(比如内核代码占用的空间)。第二个表示此页是否是free的。如果设置为1,表示这页是free的,可以被分配;如果设置为0,表示这页已经被分配出去了,不能被再二次分配。property用来记录某连续内存空闲块的大小,这里需要注意的是用到此成员变量的这个 Page 一定是连续内存块的开始地址 Base(第一页的地址)。page_link是便于把多个连续内存空闲块链接在一起的双向链表指针,连续内存空闲块利用这个页的成员变量page_link来链接比它地址小和大的其他连续内存空闲块,同样,用到此成员变量的这个 Page 一定是连续内存块的开始地址 Base(第一页的地址)。
修改函数
为了实现 FIRST_FIT ,我们需要修改如下函数:
- default_init
-
default_init_memmap
- default_alloc_pages
- default_free_pages
default_init:
- 功能: 对 free_area_t 的双向链表和空闲块的数目进行初始化
- 修改: 无需修改
1
2
3
4
5
6
//对free_area_t的双向链表和空闲块的数目进行初始化
static void
default_init(void) {
list_init(&free_list);
nr_free = 0;
}
default_init_memmap:
-
功能: 初始化空闲页链表
Page,初始化每一个空闲页,然后计算空闲页的总数 -
修改思路:
先传入物理页基地址和物理页的个数(个数必须大于 0 ),然后对每一块物理页进行设置:
先判断是否为保留页,如果不是,则进行下一步。
将标志位清 0,连续空页个数清 0,然后将标志位设置为 1,将引用此物理页的虚拟页的个数清 0。
然后再加入空闲链表。最后计算空闲页的个数,修改物理基地址页的 property 的个数为 n。
first-fit算法要求将空闲内存块按照地址从小到大的方式连起来,所以将基址页加到空闲管理列表时,应该使用函数list_add_before
修改前:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
static void
default_init_memmap(struct Page *base, size_t n) { //基地址和物理页数量
assert(n > 0);
struct Page *p = base;
for (; p != base + n; p ++) { //处理每一页
assert(PageReserved(p)); //是否为保留页
p->flags = p->property = 0; //标志位清零, 空闲块数量
set_page_ref(p, 0); //将引用此物理页的虚拟页的个数清0
}
base->property = n; //开头页面的空闲块数量设置为n
SetPageProperty(base);
nr_free += n; //新增空闲页个数nr_free
list_add(&free_list, &(base->page_link)); //将新增的Page加在双向链表指针中
}
修改后:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
static void
default_init_memmap(struct Page *base, size_t n) { //基地址和物理页数量
assert(n > 0);
struct Page *p = base;
for (; p != base + n; p ++) { //处理每一页
assert(PageReserved(p)); //是否为保留页
p->flags = p->property = 0; //标志位清零, 空闲块数量
set_page_ref(p, 0); //将引用此物理页的虚拟页的个数清0
}
base->property = n; //开头页面的空闲块数量设置为n
SetPageProperty(base);
nr_free += n; //新增空闲页个数nr_free
list_add_before(&free_list, &(base->page_link));//将新增的Page加在双向链表指针中
}
default_alloc_pages:
-
功能:
FIRST FIT 分配, 从空闲页块的链表中去遍历,找到第一块大小大于 n 的块,然后分配出来,把它从空闲页链表中除去,然后如果有多余的,把分完剩下的部分再次加入会空闲页链表中
-
修改思路:
首先判断空闲页的大小是否大于所需的页块大小。
如果需要分配的页面数量 n,已经大于了空闲页的数量,那么直接 return NULL 分配失败。
过了这一个检查之后,遍历整个空闲链表。如果找到合适的空闲页,即 p->property >= n(从该页开始,连续的空闲页数量大于n),即可认为可分配,重新设置标志位。具体操作是调用 SetPageReserved(pp) 和 ClearPageProperty(pp) ,设置当前页面预留,以及清空该页面的连续空闲页面数量值。
然后从空闲链表,即 free_area_t 中,记录空闲页的链表,删除此项。
如果当前空闲页的大小大于所需大小。则分割页块。具体操作就是,刚刚分配了n个页,如果分配完了,还有连续的空间,则在最后分配的那个页的下一个页(未分配),更新它的连续空闲页值。如果正好合适,则不进行操作。
最后计算剩余空闲页个数并返回分配的页块地址。
修改前:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static struct Page *
default_alloc_pages(size_t n) {
assert(n > 0);
if (n > nr_free) { //检查空闲页的大小是否大于所需的页块大小
return NULL;
}
struct Page *page = NULL;
list_entry_t *le = &free_list;
while ((le = list_next(le)) != &free_list) { //遍历链表找到合适的空闲页
struct Page *p = le2page(le, page_link);
if (p->property >= n) { //第一个目标页
page = p;
break;
}
}
if (page != NULL) {
list_del(&(page->page_link));
if (page->property > n) {
struct Page *p = page + n;
p->property = page->property - n;
// 注意这一步
list_add(&free_list, &(p->page_link));
}
nr_free -= n;
ClearPageProperty(page);
}
return page;
}
修改后:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static struct Page *
default_alloc_pages(size_t n) {
assert(n > 0);
if (n > nr_free) { //检查空闲页的大小是否大于所需的页块大小
return NULL;
}
struct Page *page = NULL;
list_entry_t *le = &free_list;
while ((le = list_next(le)) != &free_list) { //遍历链表找到合适的空闲页
struct Page *p = le2page(le, page_link);
if (p->property >= n) { //第一个目标页
page = p;
break;
}
}
if (page != NULL) { //如果页的空闲块数量大于n 执行分割
if (page->property > n) {
struct Page *p = page + n; //指针后移n单位
p->property = page->property - n; //数量减n
SetPageProperty(p); //调SetPageProperty设置当前页面预留
list_add(&(page->page_link), &(p->page_link)); //链接被分割之后剩下的空闲块地址
}
list_del(&(page->page_link)); //删除pageLink链接
nr_free -= n; //更新空闲页个数
ClearPageProperty(page); //清空该页面的连续空闲页面数量值
}
return page;
}
default_free_pages()
- 功能: 对页的释放操作
- 修改思路:
首先检查基地址所在的页是否为预留,如果不是预留页,那么说明它已经是 free 状态,无法再次 free,只有处在占用的页,才能有 free操作,接着,声明一个页 p,p 遍历一遍整个物理空间,直到遍历到 base 所在位置停止,开始释放操作,找到了这个基地址之后,将空闲页重新加进来(之前在分配的时候删除),设置一系列标记位,检查合并, 如果插入基地址附近的高地址或低地址可以合并,那么需要更新相应的连续空闲页数量,向高合并和向低合并。使用 list_add 默认会在函数末尾处,将待释放的页头插入至链表的第一个节点,所以我们需要修改这部分代码,使其按地址顺序插入至对应的链表结点处。
- 查看
memlayout.h
1
2
#define PG_reserved 0 // 如果被内核保留, 说明不能被分配释放
#define PG_property 1 // 只有head页需要设置property and can be used in alloc_pages
- 代码实现:
修改前:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
static void
default_free_pages(struct Page *base, size_t n) {
assert(n > 0);
struct Page *p = base;
for (; p != base + n; p ++) {
assert(!PageReserved(p) && !PageProperty(p));
p->flags = 0;
set_page_ref(p, 0);
}
base->property = n;
SetPageProperty(base);
list_entry_t *le = list_next(&free_list);
while (le != &free_list) {
p = le2page(le, page_link);
le = list_next(le);
if (base + base->property == p) {
base->property += p->property;
ClearPageProperty(p);
list_del(&(p->page_link));
}
else if (p + p->property == base) {
p->property += base->property;
ClearPageProperty(base);
base = p;
list_del(&(p->page_link));
}
}
nr_free += n;
list_add(&free_list, &(base->page_link));
}
修改后:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
static void
default_free_pages(struct Page *base, size_t n) {
assert(n > 0);
struct Page *p = base;
for (; p != base + n; p ++) { //遍历整个物理空间
assert(!PageReserved(p) && !PageProperty(p)); //检查是否是预留或者head页,内核保留无法分配释放, 只有PageProperty有效才是!free状态
p->flags = 0; //设置flage标志
set_page_ref(p, 0); //将引用此物理页的虚拟页的个数清0, 这里类似与初始化的设置
}
base->property = n; //设置空闲块数量
SetPageProperty(base); //调SetPageProperty设置当前页面预留仅仅head
list_entry_t *le = list_next(&free_list); //新建一个管理结构,为链表头的子节点
while (le != &free_list) { //遍历
p = le2page(le, page_link); //新页le2page就是初始化为一个Page结构
le = list_next(le); //取下一个节点
//向高地址合并
if (base + base->property == p) { //如果到达当前页的尾部地址,执行合并
base->property += p->property; //增加头页的property
ClearPageProperty(p); //清空该页面的连续空闲页面数量值
list_del(&(p->page_link)); //删除旧的索引
}
//向低地址合并
else if (p + p->property == base) { //同上
p->property += base->property; //增加头页的property
ClearPageProperty(base); //clear
base = p; //迭代交换base
list_del(&(p->page_link)); //删除旧的索引
}
}
//检查合并结果是否发生了错误
nr_free += n; //新增空闲快数量
le = list_next(&free_list);
while (le != &free_list) {
p = le2page(le, page_link);
if (base + base->property <= p) { //如果当前页的尾部地址小于等于p
assert(base + base->property != p); //检查是否不等于p
break;
}
le = list_next(le);
}
list_add_before(le, &(base->page_link)); //将新增的Page加在双向链表指针中
}
回答问题
你的first fit算法是否有进一步的改进空间?
在本实验中所实现的 first fit 算法仍然有着相当的改进空间,其中最主要的不足我认为就在于时间效率上,每次查询第一块符合条件的空闲内存块时,最坏情况需要找遍整个链表,这样的话时间复杂度是 $O(N)$,N 表示当前的链表大小,考虑针对时间效率的优化方式如下:
- 采用 splay 等平衡二叉树结构来取代简单的链表结构来维护空闲块,其中按照中序遍历得到的空闲块序列的物理地址恰好按照从小到大排序
- 每个二叉树节点上维护该节点为根的子树上的最大的空闲块的大小
- 在每次进行查询的时候,不妨从根节点开始,查询左子树的最大空闲块是否符合要求,如果是的话进入左子树进行进一步查询,否则进入右子树(二分查找)
- 按照上述方法,最终可以查找到物理地址最小的能够满足条件的空闲地址块,将其 splay 到平衡树的根(如果使用 splay 树的话),然后进行删除以及新的分裂出来的空闲块的插入等操作;
- 按照上述方法的话,每次查询符合条件的第一块物理空闲块的时间复杂度为 $O(logN)$,对比原先的 $O(N)$ 有了较大的改进;
练习2:实现寻找虚拟地址对应的页表项
完成 get_pte 函数
功能: 寻找虚拟地址对应的页表项, 函数找到一个虚地址对应的二级页表项的内核虚地址,如果此二级页表项不存在,则分配一个包含此项的二级页表。
实现思路:
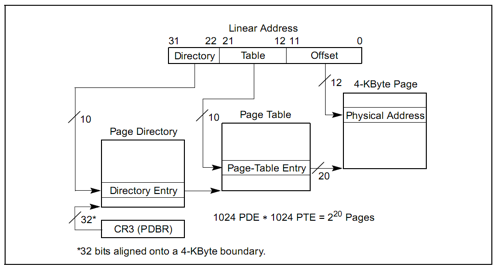
由于我们已经具有了一个物理内存页管理器 default_pmm_manager,我们就可以用它来获得所需的空闲物理页。 在二级页表结构中,页目录表占 4KB 空间,ucore 就可通过 default_pmm_manager 的 default_alloc_pages 函数获得一个空闲物理页,这个页的起始物理地址就是页目录表的起始地址。同理,ucore 也通过这种方式获得各个页表所需的空间。页表的空间大小取决与页表要管理的物理页数 n,一个页表项( 32 位,即 4 字节)可管理一个物理页,页表需要占 n/1024 个物理页空间(向上取整)。这样页目录表和页表所占的总大小约为 4096+4∗n 字节。根据 LAZY,这里我们并没有一开始就存在所有的二级页表,而是等到需要的时候再添加对应的二级页表。
当建立从一级页表到二级页表的映射时,需要注意设置控制位。这里应该设置同时设置 上 PTE_U、PTE_W 和 PTE_P(定义可在mm/mmu.h)。
如果原来就有二级页表,或者新建立了页表,则只需返回对应项的地址即可。
如果 create 参数为 0,则 get_pte 返回 NULL ,如果 create 参数不为 0,则 get_pte 需要申请一个新的物理页 然后根据注释一步步操作,代码展示如下:
1
2
3
4
5
6
pde_t 全称为page directory entry,也就是一级页表的表项
pte_t 全称为page table entry,表示二级页表的表项。
uintptr_t 表示为线性地址,由于段式管理只做直接映射,所以它也是逻辑地址。
PTE_U: 位3,表示用户态的软件可以读取对应地址的物理内存页内容
PTE_W: 位2,表示物理内存页内容可写
PTE_P: 位1,表示物理内存页存在
代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
pte_t *
get_pte(pde_t *pgdir, uintptr_t la, bool create) {
//代码实现部分8steps
pde_t *pdep = &pgdir[PDX(la)]; //取出1级表项,两个过程: 1. 线性虚拟地址la >> 页目录索引
//2.用页目录索引PDX查找页目录pgdir
if (!(*pdep & PTE_P)) { //检查项是否不存在 PTE_P 页目录或页表的 Present 位
struct Page *page; //不存在则构建
if (!create || (page = alloc_page()) == NULL) { //构建失败
return NULL;
}
set_page_ref(page, 1); //设置引用计数, 被映射了多少次
uintptr_t pa = page2pa(page); //取物理地址, page2ppn(page) << PGSHIFT;
memset(KADDR(pa), 0, PGSIZE); //clear清零页面
*pdep = pa | PTE_U | PTE_W | PTE_P; //设置页面目录条目的权限,
// PTE_U: 位3,表示用户态的软件可以读取对应地址的物理内存页内容
// PTE_W: 位2,表示物理内存页内容可写
// PTE_P: 位1,表示物理内存页存在
}
return &((pte_t *)KADDR(PDE_ADDR(*pdep)))[PTX(la)]; //拼接,返回虚拟地址, KADDR: pa >> va, PTX: la >> 页目录索引
}
回答问题
- 请描述页目录项(Page Directory Entry)和页表项(Page Table Entry)中每个组成部分的含义以及对ucore而言的潜在用处。
页目录项是指向储存页表的页面的, 所以本质上与页表项相同, 结构也应该相同。每个页表项的高 20 位, 就是该页表项指向的物理页面的首地址的高 20 位(当然物理页面首地址的低 12 位全为零), 而每个页表项的低 12 位, 则是一些功能位, 可以通过在 mmu.h 中的一组宏定义发现。对于实现页替换算法来说,页目录项(pgdir)作为一个双向链表存储了目前所有的页的物理地址和逻辑地址的对应,即在实内存中的所有页,替换算法中被换出的页从 pgdir 中选出。
接下来描述页目录项的每个组成部分,PDE(页目录项)的具体组成如下图所示;描述每一个组成部分的含义如下:
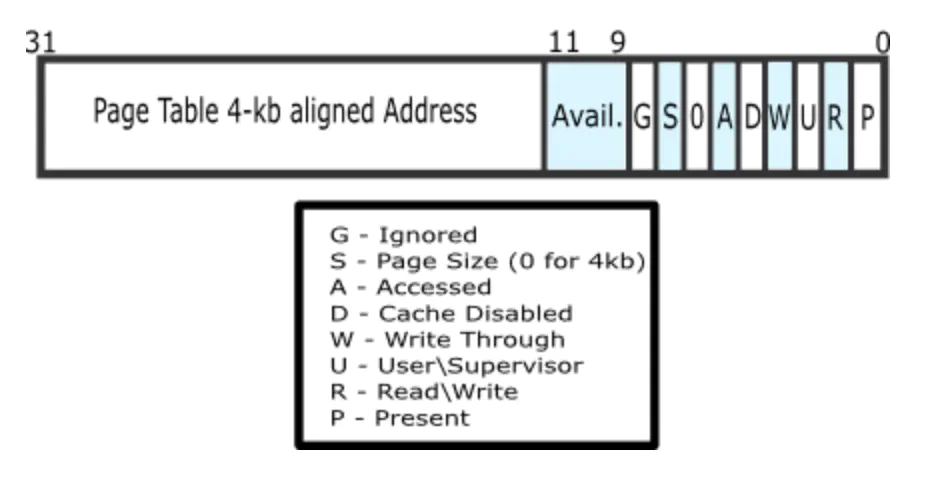
- 前 20 位表示 4K 对齐的该 PDE 对应的页表起始位置(物理地址,该物理地址的高 20 位即 PDE 中的高 20 位,低 12 位为 0);
- 第 9-11 位未被CPU使用,可保留给 OS 使用;
- 接下来的第 8 位可忽略;
- 第 7 位用于设置 Page 大小,0 表示 4KB;
- 第 6 位恒为 0;
- 第 5 位用于表示该页是否被使用过;
- 第 4 位设置为 1 则表示不对该页进行缓存;
- 第 3 位设置是否使用 write through 缓存写策略;
- 第 2 位表示该页的访问需要的特权级;
- 第 1 位表示是否允许读写;
- 第 0 位为该PDE的存在位;
页表项(PTE)则存储了替换算法中被换入的页的信息,替换后会将其映射到一物理地址。
接下来描述页表项(PTE)中的每个组成部分的含义,具体组成如下图所示:
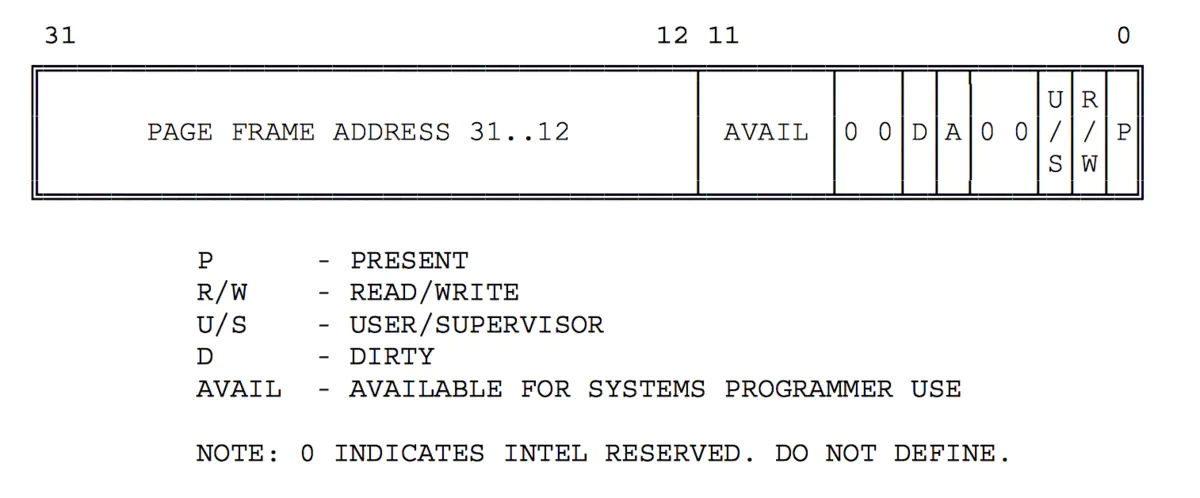
- 高 20 位与 PDE 相似的,用于表示该 PTE 指向的物理页的物理地址;
- 第 9-11 位保留给 OS 使用;
- 第 7-8 位恒为 0;
- 第 6 位表示该页是否为 dirty,即是否需要在 swap out 的时候写回外存;
- 第 5 位表示是否被访问;
- 第 3-4 位恒为 0;
- 第 0-2 位分别表示存在位、是否允许读写、访问该页需要的特权级;
对ucore的潜在用处:
可以发现无论是 PTE 还是 PDE ,都具有着一些保留的位供操作系统使用,也就是说 ucore 可以利用这些位来完成一些其他的内存管理相关的算法,比如可以在这些位里保存最近一段时间内该页的被访问的次数(仅能表示 0-7 次),用于辅助近似地实现虚拟内存管理中的换出策略的 LRU 之类的算法;也就是说这些保留位有利于 OS 进行功能的拓展;
- 如果ucore执行过程中访问内存,出现了页访问异常,请问硬件要做哪些事情?
产生页访问异常后,CPU 把引起页访问异常的线性地址装到寄存器 CR2 中,ucore 会把这个值保存在 struct trapframe 中 tf_err 成员变量中。而中断服务例程会具体处理。
当ucore执行过程中出现了页访问异常,硬件需要完成的事情分别如下:
- 将发生错误的线性地址保存在 cr2 寄存器中, 并给出了出错码 errorCode,说明了页访问异常的类型.
- 在中断栈中依次压入 EFLAGS,CS,EIP,给出页访问异常码 error code,如 pagefault 发生在用户态,则还需先压入 ss 和 esp,切换到内核栈;(中断处理)
- 根据中断描述符表查询到对应 page fault 的 ISR,跳转到对应的 ISR 处执行,接下来将由软件(如页访问异常处理函数 do_pgfault )进行 page fault 处理;
练习3:释放某虚地址所在的页并取消对应二级页表项的映射
完成 page_remove_pte 函数
函数功能: 释放某虚地址所在的页并取消对应二级页表项的映射
实现思路:
当释放一个包含某虚地址的物理内存页时,需要让对应此物理内存页的管理数据结构Page做相关的清除处理,使得此物理内存页成为空闲;另外还需把表示虚地址与物理地址对应关系的二级页表项清除。
思路主要就是先判断该页被引用的次数,如果只被引用了一次,那么就要释放掉这页,然后就要刷新 TLB,使 TLB 条目无效
取消页表映射过程如下:
- 将物理页的引用数目减一,如果变为零,那么释放页面;
- 将页目录项清零;
- 刷新TLB。
1
2
3
4
5
6
7
8
9
10
11
12
13
//释放某虚地址所在的页并取消对应二级页表项的映射
static inline void
page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep) {
//具体实现
if (*ptep & PTE_P) { //检查当前页表项是否存在
struct Page *page = pte2page(*ptep); //找到pte对应的页面
if (page_ref_dec(page) == 0) { //如果当前页面只被引用了1次
free_page(page); //那么直接释放该页
}
*ptep = 0;
tlb_invalidate(pgdir, la); //刷新TLB, 使TLB条目无效
}
}
回答问题
- 数据结构Page的全局变量(其实是一个数组)的每一项与页表中的页目录项和页表项有无对应关系?如果有,其对应关系是啥?
页目录项或者页表项中都保存着一个物理页面的地址,对于页目录项,这个物理页面用于保存二级页表,对于页表来说,这个物理页面用于内核或者用户程序。同时,每一个物理页面在Page数组中都有对应的记录。
- **如果希望虚拟地址与物理地址相等,则需要如何修改lab2,完成此事? **
过程如下:
- 修改链接脚本,将内核起始虚拟地址修改为
0x100000;
tools/kernel.ld
SECTIONS {
/* Load the kernel at this address: "." means the current address */
. = 0x100000;
...
- 修改虚拟内存空间起始地址为0;
kern/mm/memlayout.hc
1
2
/* All physical memory mapped at this address */
#define KERNBASE 0x00000000
- 注释掉取消0~4M区域内存页映射的代码
kern/mm/pmm.c
1
2
3
4
5
6
//disable the map of virtual_addr 0~4M
// boot_pgdir[0] = 0;
//now the basic virtual memory map(see memalyout.h) is established.
//check the correctness of the basic virtual memory map.
// check_boot_pgdir();
检验
在终端输入 make qemu ,得到如下结果:
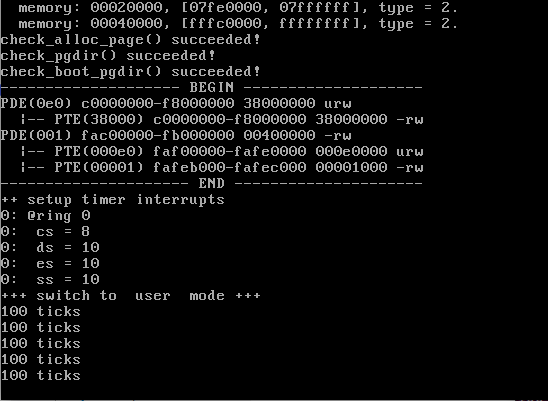
可以看到检验无误,再输入 make grade 进行检测:

可以看到得分为满分,检验成功
扩展练习Challenge:buddy system(伙伴系统)分配算法
buddy system(伙伴系统)分配算法
Buddy System算法把系统中的可用存储空间划分为存储块(Block)来进行管理, 每个存储块的大小必须是2的n次幂(Pow(2, n)), 即1, 2, 4, 8, 16, 32, 64, 128…
a. 前置准备
伙伴系统中每个存储块的大小都必须是2的n次幂,所以其中必须有个可以将传入数转换为最接近该数的2的n次幂的函数,相关代码如下
1
2
3
4
5
6
7
8
9
COPY// 传入一个数,返回最接近该数的2的指数(包括该数为2的整数这种情况)
size_t getLessNearOfPower2(size_t x)
{
size_t _i;
for(_i = 0; _i < sizeof(size_t) * 8 - 1; _i++)
if((1 << (_i+1)) > x)
break;
return (size_t)(1 << _i);
}
b. 初始化
初始时,程序会多次将一块尺寸很大的物理内存空间传入init_memmap函数,但该物理内存空间的大小却不一定是2的n次幂,所以需要对其进行分割。设定分割后的内存布局如下
1
2
3
4
5
6
7
8
9
10
COPY/*
buddy system中的内存布局
某块较大的物理空间
低地址 高地址
+-+--+----+--------+-------------------+
| | | | | |
+-+--+----+--------+-------------------+
低地址的内存块较小 高地址的内存块较大
*/
同时,在双向链表free_area.free_list中,令空间较小的内存块在双向链表中靠前,空间较大的内存块在双向链表中靠后;低地址在前,高地址在后。故以下是最终的链表布局:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
COPY/*
free_area.free_list中的内存块顺序:
1. 一大块连续物理内存被切割后,free_area.free_list中的内存块顺序
addr: 0x34 0x38 0x40
+----+ +--------+ +---------------+
<-> | 0x4| <-> | 0x8 | <-> | 0x10 | <->
+----+ +--------+ +---------------+
2. 几大块物理内存(这几块之间可能不连续)被切割后,free_area.free_list中的内存块顺序
addr: 0x34 0x104 0x38 0x108 0x40 0x110
+----+ +----+ +--------+ +--------+ +---------------+ +---------------+
<-> | 0x4| <-> | 0x4| <-> | 0x8 | <-> | 0x8 | <-> | 0x10 | <-> | 0x10 | <->
+----+ +----+ +--------+ +--------+ +---------------+ +---------------+
*/
根据上面的内存规划,可以得到buddy_init_memmap的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
COPYstatic void
buddy_init_memmap(struct Page *base, size_t n) {
assert(n > 0);
// 设置当前页向后的curr_n个页
struct Page *p = base;
for (; p != base + n; p ++) {
assert(PageReserved(p));
p->flags = p->property = 0;
set_page_ref(p, 0);
}
// 设置总共的空闲内存页面
nr_free += n;
// 设置base指向尚未处理内存的end地址
base += n;
while(n != 0)
{
size_t curr_n = getLessNearOfPower2(n);
// 向前挪一块
base -= curr_n;
// 设置free pages的数量
base->property = curr_n;
// 设置当前页为可用
SetPageProperty(base);
// 按照块的大小来插入空闲块,从小到大排序
// @note 这里必须使用搜索的方式来插入块而不是直接list_add_after(&free_list),因为存在大的内存块不相邻的情况
list_entry_t* le;
for(le = list_next(&free_list); le != &free_list; le = list_next(le))
{
struct Page *p = le2page(le, page_link);
// 排序方式以内存块大小优先,地址其次。
if((p->property > base->property)
|| (p->property == base->property && p > base))
break;
}
list_add_before(le, &(base->page_link));
n -= curr_n;
}
}
c. 空间分配
分配空间时,遍历双向链表,查找大小合适的内存块。
-
若链表中不存在合适大小的内存块,则对半切割遍历过程中遇到的第一块大小大于所需空间的内存块。
-
如果切割后的两块内存块的大小还是太大,则继续切割第一块内存块。
-
循环该操作,直至切割出合适大小的内存块。
-
最终
buddy_alloc_pages代码如下1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
COPYstatic struct Page * buddy_alloc_pages(size_t n) { assert(n > 0); // 向上取2的幂次方,如果当前数为2的幂次方则不变 size_t lessOfPower2 = getLessNearOfPower2(n); if (lessOfPower2 < n) n = 2 * lessOfPower2; // 如果待分配的空闲页面数量小于所需的内存数量 if (n > nr_free) { return NULL; } // 查找符合要求的连续页 struct Page *page = NULL; list_entry_t *le = &free_list; while ((le = list_next(le)) != &free_list) { struct Page *p = le2page(le, page_link); if (p->property >= n) { page = p; break; } } // 如果需要切割内存块时,一定分配切割后的前面那块 if (page != NULL) { // 如果内存块过大,则持续切割内存 while(page->property > n) { page->property /= 2; // 切割出的右边那一半内存块不用于内存分配 struct Page *p = page + page->property; p->property = page->property; SetPageProperty(p); list_add_after(&(page->page_link), &(p->page_link)); } nr_free -= n; ClearPageProperty(page); assert(page->property == n); list_del(&(page->page_link)); } return page; }
d. 内存释放
释放内存时
-
先将该内存块按照内存块大小从小到大与内存块地址从小到大的顺序插入至双向链表(具体请看上面的链表布局)。
-
尝试向前合并,一次就够。如果向前合并成功,则一定不能再次向前合并。
-
之后循环向后合并,直至无法合并。
需要注意的是,在查找两块内存块能否合并时,若当前内存块合并过,则其大小会变为原来的2倍,此时需要遍历比原始大小(合并前内存块大小)更大的内存块。
-
判断当前内存块的位置是否正常,如果不正常,则需要断开链表并重新插入至新的位置。
如果当前内存块没有合并则肯定正常,如果合并过则不一定异常。
-
最终代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
COPYstatic void buddy_free_pages(struct Page *base, size_t n) { assert(n > 0); // 向上取2的幂次方,如果当前数为2的幂次方则不变 size_t lessOfPower2 = getLessNearOfPower2(n); if (lessOfPower2 < n) n = 2 * lessOfPower2; struct Page *p = base; for (; p != base + n; p ++) { assert(!PageReserved(p) && !PageProperty(p)); p->flags = 0; set_page_ref(p, 0); } base->property = n; SetPageProperty(base); nr_free += n; list_entry_t *le; // 先插入至链表中 for(le = list_next(&free_list); le != &free_list; le = list_next(le)) { p = le2page(le, page_link); if ((base->property <= p->property) || (p->property == base->property && p > base))) { break; } } list_add_before(le, &(base->page_link)); // 先向左合并 if(base->property == p->property && p + p->property == base) { p->property += base->property; ClearPageProperty(base); list_del(&(base->page_link)); base = p; le = &(base->page_link); } // 之后循环向后合并 // 此时的le指向插入块的下一个块 while (le != &free_list) { p = le2page(le, page_link); // 如果可以合并(大小相等+地址相邻),则合并 // 如果两个块的大小相同,则它们不一定内存相邻。 // 也就是说,在一条链上,可能存在多个大小相等但却无法合并的块 if (base->property == p->property && base + base->property == p) { // 向右合并 base->property += p->property; ClearPageProperty(p); list_del(&(p->page_link)); le = &(base->page_link); } // 如果遍历到的内存块一定无法合并,则退出 else if(base->property < p->property) { // 如果合并不了,则需要修改base在链表中的位置,使大小相同的聚在一起 list_entry_t* targetLe = list_next(&base->page_link); p = le2page(targetLe, page_link); while(p->property < base->property) || (p->property == base->property && p > base)) targetLe = list_next(targetLe); // 如果当前内存块的位置不正确,则重置位置 if(targetLe != list_next(&base->page_link)) { list_del(&(base->page_link)); list_add_before(targetLe, &(base->page_link)); } // 最后退出 break; } le = list_next(le); } }
e. 算法检查
buddy_check是一个不能忽视的检查函数,该函数可以帮助查找出程序内部隐藏的bug。笔者将其中原本用于检查FIFO算法的内容修改成检查buddySystem的内容。所修改的内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
COPY//.........................................................
// 先释放
free_pages(p0, 26); // 32+ (-:已分配 +: 已释放)
// 首先检查是否对齐2
p0 = alloc_pages(6); // 8- 8+ 16+
p1 = alloc_pages(10); // 8- 8+ 16-
assert((p0 + 8)->property == 8);
free_pages(p1, 10); // 8- 8+ 16+
assert((p0 + 8)->property == 8);
assert(p1->property == 16);
p1 = alloc_pages(16); // 8- 8+ 16-
// 之后检查合并
free_pages(p0, 6); // 16+ 16-
assert(p0->property == 16);
free_pages(p1, 16); // 32+
assert(p0->property == 32);
p0 = alloc_pages(8); // 8- 8+ 16+
p1 = alloc_pages(9); // 8- 8+ 16-
free_pages(p1, 9); // 8- 8+ 16+
assert(p1->property == 16);
assert((p0 + 8)->property == 8);
free_pages(p0, 8); // 32+
assert(p0->property == 32);
// 检测链表顺序是否按照块的大小排序的
p0 = alloc_pages(5);
p1 = alloc_pages(16);
free_pages(p1, 16);
assert(list_next(&(free_list)) == &((p1 - 8)->page_link));
free_pages(p0, 5);
assert(list_next(&(free_list)) == &(p0->page_link));
p0 = alloc_pages(5);
p1 = alloc_pages(16);
free_pages(p0, 5);
assert(list_next(&(free_list)) == &(p0->page_link));
free_pages(p1, 16);
assert(list_next(&(free_list)) == &(p0->page_link));
// 还原
p0 = alloc_pages(26);
//.........................................................
f. 总结与完整代码
-
buddySystem在所分配的内存大小均为2的n次幂这种环境下,使用效果极佳。 -
由于
buddySystem的特性,最好使用二叉树而非普通双向链表来管理内存块,这样就可以避免一系列的bug。即便普通双向链表可以很好的实现
buddySystem,但其中仍然存在一个较为麻烦的问题:当某个物理块释放,将其插入至双向链表后,如果该物理块既可以和上一个物理块合并,又可以和下一个物理块合并,那么此时该合并哪一个物理块?
这个问题,双向链表无法很好的解决,该问题很可能会使一些物理块因为错误的合并顺序而最终导致内存的碎片化,降低内存的使用率。
扩展练习Challenge:任意大小的内存单元slub分配算法
slub算法,实现两层架构的高效内存单元分配,第一层是基于页大小的内存分配,第二层是在第一层基础上实现基于任意大小的内存分配。可简化实现,能够体现其主体思想即可。
Challenges是选做,做一个就很好了。完成Challenge的同学可单独提交Challenge。完成得好的同学可获得最终考试成绩的加分。
重要知识点
1.特权级以及特权级的转换
特权级的目的:用于操作系统和CPU提供给不同应用程序隔离空间、不能让用户程序任意访问操作系统空间
X86的特权级共4个,分别为:ring 0内核级,ring 1和2 操作系统的一些服务、ring 3 应用程序级(用户态),不过在Linux以及ucore中只使用了两个级别:ring 0内核级—-用于操作系统访问数据、运行以及执行一些特权指令, ring 3 应用程序级(用户态)—-访问应用程序层面的数据以及执行用户代码等。由于保护机制的存在,使得如果处于用户态去访问特权指令,会导致中断。
很重要!了解CPL、DPL、RPL以及它们的区别k而参考链接 https://blog.csdn.net/bfboys/article/details/52420211
-
CPL:当前特权级(Current Privilege Level),保存在 CS段寄存器(选择子)的最低两位, CPL 就是当前活动代码段的特权级,并且它定义了当前所执行程序的特权级别)
-
DPL:描述符特权(Descriptor Privilege Level),存储在段描述符中的权限位,用于描述对应段所属的特权等级,也就是段本身真正的特权级。
-
RPL:请求特权级RPL(Request Privilege Level) ,RPL保存在段选择子的最低两位。 每个段选择子有自己的RPLRPL说明的是进程对段访问的请求权限,意思是当前进程想要的请求权限。
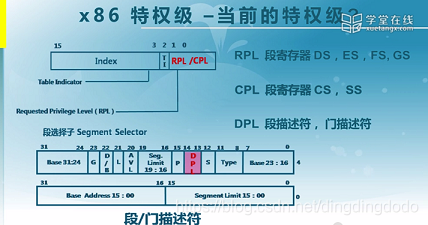
特权级的检查:

下面说明操作系统如何实现特权级的切换(基于lab1中对中断的理解):
(在lab1的challenge中已经实现特权级切换,通过调用软中断i()的方式,在此处进行细节说明):
由lab1可知任务门描述符、中断门描述符、陷阱门描述符的格式:

发生中断时操作系统将由用户态跳转至内核态,在内核态的堆栈中保存相关信息。

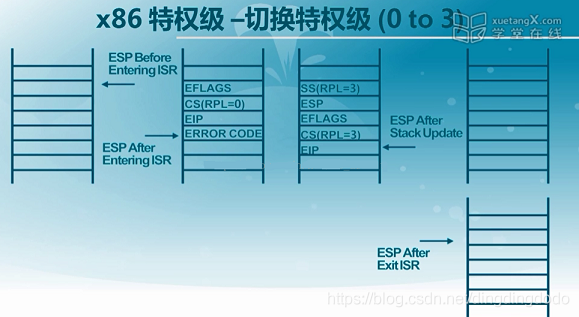
- 实现从特权级0到特权级3的切换(内核态到用户态):
按照我的理解就是通过构造一个能够从ring0返回到ring3的栈来实现,这个中断栈通过内核实现模拟,保存的信息包括EIP、ERROR CODE、CS、EFLAGS。之后通过IRET指令完成数据的更新,完成寄存器的更新,从而实现转换,具体可以用下图表示:
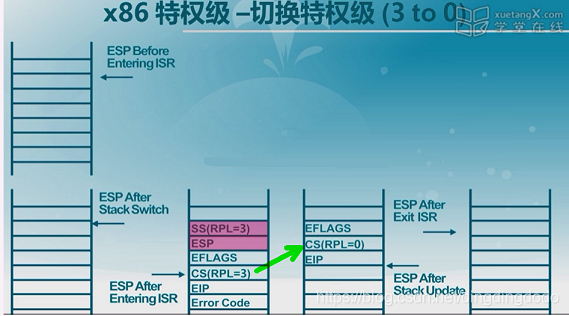
- 实现特权级3到特权级0的转变(用户态到内核态)
通常操作系统会采用软中断或者叫做trap的方式完成。实际上,发生中断时已经实现了从用户态切换到内核态,为了实现这种切换,我们需要建立好中断门,中断门中的中断描述符表指出了中断发生后跳转至何处,并且发生中断时我们必须保存SS、ESP等信息。但是,中断会根据保存的这些信息返回到用户态中,为了实现停留在内核态,我们对CS进行修改,将其指向内核态的代码段,其次,我们将CS的CPL设为0,在此处还需要根据要执行的指令修改EIP,这样最后执行IRET指令时,CPU会将堆栈信息取出并返回到EIP以及CS所指内容去执行,从而便实现了从ring3到ring0的转换。
为了实现特权级的切换,实际上还需要访问TSS(Task State Segment)任务状态段。简单来说,任务状态段就是内存中的一个数据结构。这个结构中保存着和任务相关的信息。当发生任务切换的时候会把当前任务用到的寄存器内容(CS/ EIP/ DS/SS/EFLAGS…)保存在TSS 中以便任务切换回来时候继续使用。
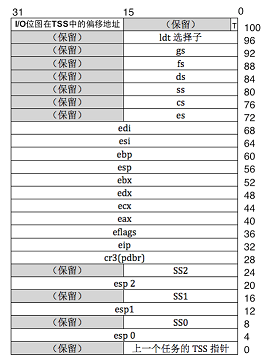
为了访问TSS,还需要访问全局描述符表。全局描述符表(GDT)保存者TSS的地址,TSS最终会被加载进内存中。其中有一个Task Register 的cache缓存,最终通过基址加上偏移来确定Task所在的具体位置。
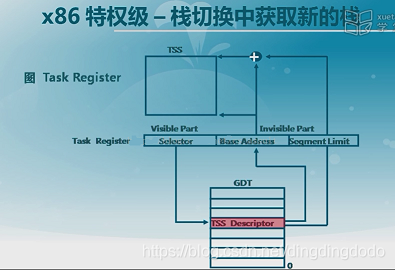
通过上述内容,我了解了什么是特权级以及如何实现特权级的检验以及切换。并且对LAB1中的中断进行了回顾与深化,对中断的相关内容有了更为深刻以及细节的认识。基本掌握了特权级的相关知识。
2.物理内存检测:
(参考自本节的附录A、B以及视频教学以及相关资料)
显然,进行物理内存空间分配前,我们必须知道现在物理内存空间的信息,包括物理内存有多大、哪些地址空间可用,哪些地址空间不可用以及它们是否是连续的可用空间等。一般来说,获取内存大小的方法由 BIOS 中断调用和直接探测两种,其中BIOS中断调用方法通常只能在实模式下完成,直接探测的方法必须在保护模式下完成。在本实验中,我们通过e820h中断获取内存信息。因为e820h中断必须在实模式下使用,所以我们在 bootloader 进入保护模式之前调用这个 BIOS 中断,并且把 e820 映射结构保存在物理地址0x8000处。具体实现如下:
首先,需要知道BIOS是通过系统内存映射地址描述符(Address Range Descriptor)格式来表示系统物理内存布局,其具体表示为
1
2
3
4
Offset Size Description
00h 8字节 base address #系统内存块基地址
08h 8字节 length in bytes #系统内存大小
10h 4字节 type of address range #内存类型
之后看一下(Values for System Memory Map address type)
1
2
3
4
5
6
Values for System Memory Map address type:
01h memory, available to OS
02h reserved, not available (e.g. system ROM, memory-mapped device)
03h ACPI Reclaim Memory (usable by OS after reading ACPI tables)
04h ACPI NVS Memory (OS is required to save this memory between NVS sessions)
other not defined yet -- treat as Reserved
然后看e820map的定义:
1
2
3
4
5
6
7
8
9
struct e820map
{
int nr_map;
struct {
uint64_t addr;
uint64_t size;
uint32_t type;
} __attribute__((packed)) map[E820MAX];
};
因此可以通过调用INT 15h BIOS中断,递增di的值(20的倍数),让BIOS帮我们查找出一个一个的内存布局entry,并放入到一个保存地址范围描述符结构的缓冲区中,供后续的ucore进一步进行物理内存管理。
在此处可以查看boot/bootasm.S 中利用汇编元具体实现物理内存检测的过程:
probe_memory:
#对0x8000处的32位单元清零,即给位于0x8000处的struct
#e820map的成员变量nr_map清零
movl $0, 0x8000
xorl %ebx, %ebx
#表示设置调用INT 15H BIOS中断后,BIOS返回的映射地址描述符的start address
movw $0x8004, %di
start_probe:
movl $0xE820, %eax
#设置地址范围描述符的大小为20字节,其大小等于struct e820map的成员变量map的大小
movl $20, %ecx
#设置edx为"SMAP",(这是通常的一个约定)
movl $SMAP, %edx
#调用ini 0x15中断,要求BIOS返回一个用地址范围描述符表示的内存段信息
int $0x15
#如果eflags的CF位为0,则表示还有内存段需要探测
jnc cont
#如果探测有问题,则结束探测
movw $12345, 0x8000
jmp finish_probe
cont:
#设置下一个BIOS返回的映射地址描述符的start address
addw $20, %di
#递增struct e820map的成员变量nr_map
incl 0x8000
#如果INT0x15返回的ebx为0,则探测结束,否则继续探测
cmpl $0, %ebx
jnz start_probe
finish_probe:
上述代码正常执行完毕后,在0x8000地址处保存了从BIOS中获得的内存分布信息。
从具体代码我们可以看出,要实现物理内存空间的探测基本上是以下三步骤:
-
设置一个存放内存映射地址描述符的物理地址(在此为0x8000)
-
将e820作为参数传递给INT 15h中断
-
通过检测eflags的CF位来判断探测是否结束。如果CF位为0,则表示探测没有结束,那么就需要设置存放下一个内存映射地址描述符的物理地址,返回步骤2继续进行否则物理内存检测就此结束。
通过代码我们也能知道实现物理内存检测后在0x8000地址处保存了从BIOS中获得的内存分布信息,此信息按照struct e820map的设置来进行填充,之后便开始执行进入保护模式的过程。
3.连续物理内存分配
连续分配方式,是指为用户程序分配一个不小于指定大小的连续的内存空间。连续物理内存分配会产生碎片,包括内部碎片(已经被分配出去的的内存空间大于请求所需的内存空间)和外部碎片(还没有分配出去,但是由于太小而无法分配给申请空间的新进程的内存空间空闲块),实际上可以通过紧凑的方式(操作系统不时地对进程进行移动和整理)或者分区交换的方式(通过抢占并回收处于等待状态进程的分区以增大可用内存空间)解决外部碎片。
动态分区分配:当程序被加载执行时,分配一个进程指定大小可变的分区(块、内存块),分区的地址是连续的。操作系统需要维护的数据结构包括所有进程的已分配分区以及空闲分区。
常见的动态分区的分配策略如下:
首次适应(First Fit)算法:空闲分区以地址递增的次序链接。分配内存时顺序查找,找到大小能满足要求的第一个空闲分区。该算法的缺点在于:低地址部分由于不断被划分,会留下许多难以利用的小空闲分区,并且,每次都从低地址开始检索,将增大可用空闲区间查找的开销。
最佳适应(Best Fit)算法:空闲分区按容量递增形成分区链,找到第一个能满足要求的空闲分区,即找到一个满足要求且最小的空闲分区分配给作业。实际上从宏观上看,存储器将留下许多难以利用的小空闲区。
最坏适应(Worst Fit)算法:空闲分区以容量递减的次序链接。找到第一个能满足要求的空闲分区,即挑选出最大的分区。该算法优点是使剩下的空闲区不至于太小,故产生碎片的几率减小。因此该算法对中小作业有利,但对大作业不利。
4.段页式管理内存
以页为单位管理物理内存
在获得可用物理内存范围后,系统需要建立相应的数据结构来管理以物理页(按4KB对齐,且大小为4KB的物理内存单元)为最小单位的整个物理内存,以配合后续涉及的分页管理机制。
我们通过查阅代码可以了解:在kern/mm/memlayout.h中,给出了page的定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//用来描述页
//描述物理空间的页
struct Page {
int ref; // page frame's reference counter
//ref表示这个页被页表的引用量
//如果这个页被页表引用了,即在某页表中有一个页表项设置了一个虚拟页到这个Page管理的物理页的映射关系
//,就会把Page的ref加一;反之,若页表项取消,即映射关系解除,就会把Page的ref减一。
uint32_t flags; // array of flags that describe the status of the page frame
//flags标记是否可以被分配
unsigned int property; // the num of free block, used in first fit pm manager
//property用来记录连续空闲页的数量,
list_entry_t page_link; // free list link
//双向链表,空闲页构成链表
};
由于所有的连续内存空闲块可用一个双向链表管理起来,便于分配和释放,为此定义了一个free_area_t数据结构,包含了一个list_entry结构的双向链表指针和记录当前空闲页的个数的无符号整型变量nr_free。
1
2
3
4
5
6
7
/* free_area_t - maintains a doubly linked list to record free (unused) pages */
typedef struct {
list_entry_t free_list; // the list header
//列表的头
unsigned int nr_free; // # of free pages in this free list
//空闲页的数量
} free_area_t;
在pmm.c中,可以通过下面代码段,更好地理解“管理页级物理内存空间所需的Page结构的内存空间从哪里开始,占多大空间”以及“空闲内存空间的起始地址在哪里“这两个问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
//end指向bootloader加载ucore的结束地址
extern char end[];
//需要管理的物理页个数为
npage = maxpa / PGSIZE;
//由于bootloader加载ucore的结束地址以上的空间没有被使用,
//所以我们可以把end按页大小为边界去整后,作为管理页级物理内存空间所需的Page结构的内存空间
pages = (struct Page *)ROUNDUP((void *)end, PGSIZE);
//对地址空间进行标记
for (i = 0; i < npage; i ++) {
SetPageReserved(pages + i);
}
//从地址0到地址pages+ sizeof(struct Page) * npage)结束的物理内存空间设定为已占用物理内存空间
//(起始0~640KB的空间是空闲的),地址pages+ sizeof(struct Page) * npage)以上的空间为空闲物理内存空间,这时的空闲空间起始地址为
uintptr_t freemem = PADDR((uintptr_t)pages + sizeof(struct Page) * npage);
//根据begin以及end,实现空闲物理内存空间的标记
for (i = 0; i < memmap->nr_map; i ++) {
uint64_t begin = memmap->map[i].addr, end = begin + memmap->map[i].size;
if (memmap->map[i].type == E820_ARM) {
if (begin < freemem) {
begin = freemem;
}
if (end > KMEMSIZE) {
end = KMEMSIZE;
}
if (begin < end) {
begin = ROUNDUP(begin, PGSIZE);
end = ROUNDDOWN(end, PGSIZE);
if (begin < end) {
init_memmap(pa2page(begin), (end - begin) / PGSIZE);
}
}
}
}
}

当完成物理内存页管理初始化工作后,计算机系统的内存布局如下图所示(引用自gitbook):
分段机制
分段机制就是把虚拟地址空间中的虚拟内存组织成一些长度可变的称为段的内存块单元。 每个段由三个参数定义:段基地址、段限长和段属性。基本思路如图
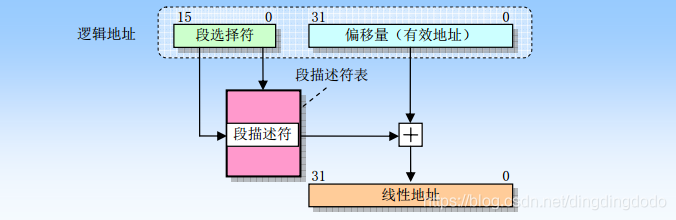
如果没有开启分页,那么处理器直接把线性地址映射到物理地址,即线性地址被送到处理器地址总线上;如果对线性地址空间进行了分页处理,那么就会使用二级地址转换把线性地址转换成物理地址。
分页机制
分页机制是 80x86 内存管理机制的第二部分。它在分段机制的基础上完成虚拟地址到物理地址的转换过程。分段机制把逻辑地址转换成线性地址,而分页机制则把线性地址转换成物理地址。
分页机制可以用下图说明:
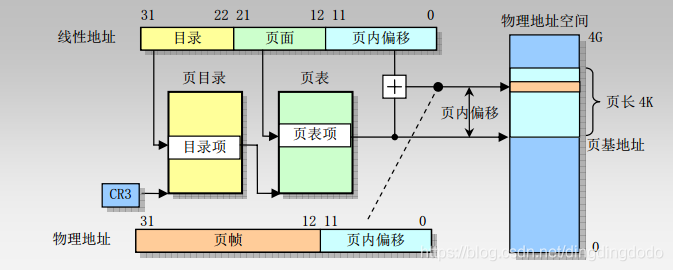
总的来说,地址的处理过程如下所示:
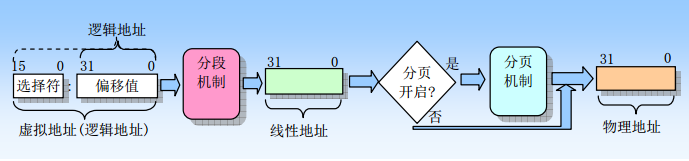
对段页式管理有了基本认识后,便可以针对具体问题去具体分析解决。
5.伙伴系统 buddy system
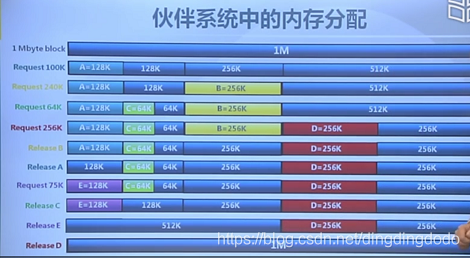
伙伴分配的实质就是一种特殊的“分离适配”,整个内存的大小是2的n次方,并将内存按2的幂进行划分。
需要分配内存的时:核心就是分配出不小于所需的最小2次幂大小的内存(如果需要25,就分配32;如果需要63,就分配64),具体分配时,如果有符合的内存块,直接分配即可;如果当前的空闲块没有满足要求的,就将大块进行二等分,继续重复分配过程。
需要释放内存时:首先将该内存块释放,然后看其相邻的块(可以进行合并的相邻块,即在分配时由一个内存块分成的两个等大内存块)是否释放,如果相邻块没有释放,则结束即可;如果相邻块释放,则将两个块合并,重复释放过程,对合并后的块进行释放。对相邻块做一个更容易实现的解释:相邻块不仅地址相邻,且二者中的低地址块的地址必须为2的整数幂。
对其原理进行一个图解(仔细观察这个图便可以了解其工作机制):
通常,我们利用满二叉树的数据结构实现buddy system。分配器的整体思想是,通过一个数组形式的完全二叉树来监控管理内存,二叉树的节点用于标记相应内存块的使用状态,高层节点对应大的块,低层节点对应小的块,在分配和释放中我们就通过这些节点的标记属性来进行块的分离合并。
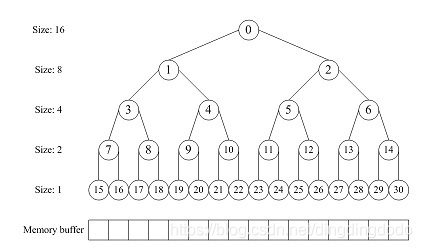
讨论一下该算法的优缺点:其优点是快速搜索合并($O(logN)$ 时间复杂度)以及低外部碎片(最佳适配best-fit);其缺点是内部碎片,因为按2的幂划分块,如果碰上65单位大小,那么必须划分128单位大小的块。
6.ucore
1) 物理内存探测
-
操作系统需要知道了解整个计算机系统中的物理内存如何分布的,哪些被可用,哪些不可用。其基本方法是通过BIOS中断调用来帮助完成的。
bootasm.S中新增了一段代码,使用BIOS中断检测物理内存总大小。 -
在讲解该部分代码前,先引入一个结构体
COPYstruct e820map { // 该数据结构保存于物理地址0x8000 int nr_map; // map中的元素个数 struct { uint64_t addr; // 某块内存的起始地址 uint64_t size; // 某块内存的大小 uint32_t type; // 某块内存的属性。1标识可被使用内存块;2表示保留的内存块,不可映射。 } __attribute__((packed)) map[E820MAX]; }; -
以下是bootasm.S中新增的代码,详细信息均以注释的形式写入代码中。
COPYprobe_memory: movl $0, 0x8000 # 初始化,向内存地址0x8000,即uCore结构e820map中的成员nr_map中写入0 xorl %ebx, %ebx # 初始化%ebx为0,这是int 0x15的其中一个参数 movw $0x8004, %di # 初始化%di寄存器,使其指向结构e820map中的成员数组map start_probe: movl $0xE820, %eax # BIOS 0x15中断的子功能编号 %eax == 0xE820 movl $20, %ecx # 存放地址范围描述符的内存大小,至少20 movl $SMAP, %edx # 签名, %edx == 0x534D4150h("SMAP"字符串的ASCII码) int $0x15 # 调用0x15中断 jnc cont # 如果该中断执行失败,则CF标志位会置1,此时要通知UCore出错 movw $12345, 0x8000 # 向结构e820map中的成员nr_map中写入特殊信息,报告当前错误 jmp finish_probe # 跳转至结束,不再探测内存 cont: addw $20, %di # 如果中断执行正常,则目标写入地址就向后移动一个位置 incl 0x8000 # e820::nr_map++ cmpl $0, %ebx # 执行中断后,返回的%ebx是原先的%ebx加一。如果%ebx为0,则说明当前内存探测完成 jnz start_probe finish_probe: -
这部分代码执行完成后,从BIOS中获得的内存分布信息以结构体
e820map的形式写入至物理0x8000地址处。稍后ucore的page_init函数会访问该地址并处理所有的内存信息。
2) 链接地址
-
审计
lab2/tools/kernel.ld这个链接脚本,我们可以很容易的发现,链接器设置kernel的链接地址(link address)为0xC0100000,这是个虚拟地址。在uCore的bootloader中,bootloader使用如下语句来加载kernel:COPYreadseg(ph->p_va & 0xFFFFFF, ph->p_memsz, ph->p_offset);0xC0010000 & 0xFFFFFF == 0x00100000即kernel最终被装载入物理地址0x10000处,其相对偏移为-0xc0000000,与uCore中所设置的虚拟地址的偏移量相对应。 -
需要注意的是,在lab2的一些代码中会使用到如下两个变量,但这两个变量并没有被定义在任何C语言的源代码中:
1 2
COPYextern char end[]; extern char edata[];
实际上,它们定义于
kernel.ld这个链接脚本中COPY. = ALIGN(0x1000); .data.pgdir : { *(.data.pgdir) } PROVIDE(edata = .); .bss : { *(.bss) } PROVIDE(end = .); /DISCARD/ : { *(.eh_frame .note.GNU-stack) } // 脚本文件的结尾edata表示kernel的data段结束地址;end表示bss段的结束地址(即整个kernel的结束地址)edata[]和end[]这些变量是ld根据kernel.ld链接脚本生成的全局变量,表示相应段的结束地址,它们不在任何一个.S、.c或.h文件中定义,但仍然可以在源码文件中使用。
3) uCore的内存空间布局
-
在uCore中,CPU先在bootasm.S(实模式)中通过调用BIOS中断,将物理内存的相关描述符写入特定位置
0x8000,然后读入kernel至物理地址0x10000、虚拟地址0xC0000000。 -
而kernel在
page_init函数中,读取物理内存地址0x8000处的内存,查找最大物理地址,并计算出所需的页面数。虚拟页表VPT(Virtual Page Table)的地址紧跟kernel,其地址为4k对齐。虚拟地址空间结构如下所示:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
COPY/* * * Virtual memory map: Permissions * kernel/user * * 4G -----------> +---------------------------------+ * | | * | Empty Memory (*) | * | | * +---------------------------------+ 0xFB000000 * | Cur. Page Table (Kern, RW) | RW/-- PTSIZE * VPT ----------> +---------------------------------+ 0xFAC00000 * | Invalid Memory (*) | --/-- * KERNTOP ------> +---------------------------------+ 0xF8000000 * | | * | Remapped Physical Memory | RW/-- KMEMSIZE * | | * KERNBASE -----> +---------------------------------+ 0xC0000000 * | | * | | * | | * ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ * (*) Note: The kernel ensures that "Invalid Memory" is *never* mapped. * "Empty Memory" is normally unmapped, but user programs may map pages * there if desired. * * */
完成物理内存页管理初始化工作后,其物理地址的分布空间如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
COPY+----------------------+ <- 0xFFFFFFFF(4GB) ---------------------------- 4GB | 一些保留内存,例如用于| 保留空间 | 32bit设备映射空间等 | +----------------------+ <- 实际物理内存空间结束地址 ---------------------------- | | | | | 用于分配的 | 可用的空间 | 空闲内存区域 | | | | | | | +----------------------+ <- 空闲内存起始地址 ---------------------------- | VPT页表存放位置 | VPT页表存放的空间 (4MB左右) +----------------------+ <- bss段结束处 ---------------------------- |uCore的text、data、bss | uCore各段的空间 +----------------------+ <- 0x00100000(1MB) ---------------------------- 1MB | BIOS ROM | +----------------------+ <- 0x000F0000(960KB) | 16bit设备扩展ROM | 显存与其他ROM映射的空间 +----------------------+ <- 0x000C0000(768KB) | CGA显存空间 | +----------------------+ <- 0x000B8000 ---------------------------- 736KB | 空闲内存 | +----------------------+ <- 0x00011000(+4KB) uCore header的内存空间 | uCore的ELF header数据 | +----------------------+ <-0x00010000 ---------------------------- 64KB | 空闲内存 | +----------------------+ <- 基于bootloader的大小 bootloader的 | bootloader的 | 内存空间 | text段和data段 | +----------------------+ <- 0x00007C00 ---------------------------- 31KB | bootloader和uCore | | 共用的堆栈 | 堆栈的内存空间 +----------------------+ <- 基于栈的使用情况 | 低地址空闲空间 | +----------------------+ <- 0x00000000 ---------------------------- 0KB
易知,其页表地址之上的物理内存空间是空闲的(除去保留的内存),故将该物理地址之下的物理空间对应的页表全部设置为保留(reserved)。并将这些空闲的内存全部添加进页表项中。
4) 段页式存储管理(重要)
在保护模式中,x86 体系结构将内存地址分成三种:逻辑地址(也称虚拟地址)、线性地址和物理地址。
- 段式存储在内存保护方面有优势,页式存储在内存利用和优化转移到后备存储方面有优势。
- 在段式存储管理基础上,给每个段加一级页表。同时,通过指向相同的页表基址,实现进程间的段共享。
- 在段页式管理中,操作系统弱化了段式管理中的功能,实现以分页为主的内存管理。段式管理只起到了一个过滤的作用,它将地址不加转换直接映射成线性地址。将虚拟地址转换为物理地址的过程如下:
- 根据段寄存器中的段选择子,获取GDT中的特定基址并加上目标偏移来确定线性地址。由于GDT中所有的基址全为0(因为弱化了段式管理的功能,对等映射),所以此时的逻辑地址和线性地址是相同的。
- 根据该线性地址,获取对应页表项,并根据该页表项来获取对应的物理地址。
- 一级页表(页目录表PageDirectoryTable, PDT)的起始地址存储于
%cr3寄存器中。
a. 启动页机制(重要)
启动页机制的代码很简单,其对应的汇编代码为
COPY# labcodes/lab2/kern/init/entry.S
kern_entry:
# load pa of boot pgdir
movl $REALLOC(__boot_pgdir), %eax
movl %eax, %cr3
# enable paging
movl %cr0, %eax
orl $(CR0_PE | CR0_PG | CR0_AM | CR0_WP | CR0_NE | CR0_TS | CR0_EM | CR0_MP), %eax
andl $~(CR0_TS | CR0_EM), %eax
movl %eax, %cr0
# update eip
# now, eip = 0x1xxxxx
leal next, %eax
# set eip = KERNBASE + 0x1xxxxx
jmp *%eax
next:
# .....省略剩余代码
# kernel builtin pgdir
# an initial page directory (Page Directory Table, PDT)
# These page directory table and page table can be reused!
.section .data.pgdir
.align PGSIZE
__boot_pgdir:
.globl __boot_pgdir
# map va 0 ~ 4M to pa 0 ~ 4M (temporary)
.long REALLOC(__boot_pt1) + (PTE_P | PTE_U | PTE_W)
.space (KERNBASE >> PGSHIFT >> 10 << 2) - (. - __boot_pgdir) # pad to PDE of KERNBASE
# map va KERNBASE + (0 ~ 4M) to pa 0 ~ 4M
.long REALLOC(__boot_pt1) + (PTE_P | PTE_U | PTE_W)
.space PGSIZE - (. - __boot_pgdir) # pad to PGSIZE
.set i, 0
__boot_pt1:
.rept 1024
.long i * PGSIZE + (PTE_P | PTE_W)
.set i, i + 1
.endr
-
首先,将一级页表 __boot_pgdir (页目录表PDT)的物理基地址加载进
%cr3寄存器中。-
该一级页表暂时将虚拟地址 0xC0000000 + (0~4M) 以及虚拟地址 (0~4M) 设置为物理地址 (0-4M) 。
之后会重新设置一级页表的映射关系。
为什么要将两段虚拟内存映射到同一段物理地址呢?思考一下,答案就在下方。
-
-
之后,设置
%cr0寄存器中PE、PG、AM、WP、NE、MP位,关闭TS 与EM 位,以启动分页机制。先介绍一下
%cr0寄存器主要3个标志位的功能:- Protection Enable: 启动保护模式,默认只是打开分段。
- Paging: 设置分页标志。只有PE和PG位同时置位,才能启动分页机制。
- Write Protection: 当该位为1时,CPU会禁止ring0代码向read only page写入数据。这个标志位主要与写时复制有关系。
除PE、PG与WP 的其他标志位与分页机制关联不大,其设置或清除的原因盲猜可能是通过启动分页机制这个机会来顺便做个初始化。
当改变PE和PG位时,必须小心。只有当执行程序至少有部分代码和数据在线性地址空间和物理地址空间中具有相同地址时,我们才能改变PG位的设置。
因为当
%cr0寄存器一旦设置,则分页机制立即开启。此时这部分具有相同地址的代码在分页和未分页之间起着桥梁的作用。无论是否开启分页机制,这部分代码都必须具有相同的地址。而这一步的操作能否成功,关键就在于一级页表的设置。一级页表将虚拟内存中的两部分地址KERNBASE+(0-4M) 与 (0-4M) 暂时都映射至物理地址 (0-4M) 处,这样就可以满足上述的要求。
-
最后,必须来个简单的
jmp指令,将eip从物理地址“修改”为虚拟地址。在修改该了PE位之后程序必须立刻使用一条跳转指令,以刷新处理器执行管道中已经获取的不同模式下的任何指令。
b. uCore段页机制启动过程
- bootloader在启动保护模式前,会设置一个临时GDT以便于进入CPU保护模式后的bootloader和uCore所使用。
- uCore被bootloader加载进内存后,在
kern_entry中启动页机制。 - 在
pmm_init中建立双向链表来管理物理内存,并设置一级页表(页目录表)与二级页表。 - 最后重新加载新的GDT。
lab2相对于lab1,新增了页机制相关的处理过程,其他过程没有改变。
c. uCore物理页结构
-
uCore中用于管理物理页的结构如下所示
1 2 3 4 5 6 7 8 9 10 11
COPY/* * * struct Page - Page descriptor structures. Each Page describes one * physical page. In kern/mm/pmm.h, you can find lots of useful functions * that convert Page to other data types, such as phyical address. * */ struct Page { int ref; // 当前页被引用的次数,与内存共享有关 uint32_t flags; // 标志位的集合,与eflags寄存器类似 unsigned int property; // 空闲的连续page数量。这个成员只会用在连续空闲page中的第一个page list_entry_t page_link; // 两个分别指向上一个和下一个非连续空闲页的指针。 };
目前在lab2中,flags可以设置的位只有
reserved位和Property位。reserved位表示当前页是否被保留,一旦保留该页,则该页无法用于分配;Property位表示当前页是否已被分配,为1则表示已分配。 -
所有的数据结构Page都存放在一维Page结构数组中。但请注意,这并非虚拟页表(VPT),即该一维Page结构数组并非分页机制用于*将虚拟地址转换为物理地址*这个过程所用到的一级与二级页表,它们只是用于设置对应物理页表的相关属性,例如当前物理页表被二级页表的引用次数等等。
-
同时,该一维Page结构数组的存储位置与虚拟页表VPT的存储位置不同。前者的起始存储地址为kernel结尾地址向上4k对齐后的第一个物理页面,而后者则存储于指定虚拟地址
0xFAC00000。 -
页目录表使用线性地址的首部(PDX, 10bit)作为索引,二级页表使用线性地址的中部(PTX, 10bit)作为索引,而Page结构数组使用物理地址的首部与中部(PPN, 20bit)作为索引(注意是物理地址)。
-
为了加快查找,所有连续空闲pages中的第一个Page结构都会构成一个双向链表。相互链接,其第一个结点是
free_area.free_list1 2 3 4 5 6
COPY/* free_area_t - maintains a doubly linked list to record free (unused) pages */ typedef struct { list_entry_t free_list; // the list header unsigned int nr_free; // # of free pages in this free list } free_area_t; free_area_t free_area;
d. 虚拟页表结构
每个页表项(PTE)都由一个32位整数来存储数据,其结构如下
1
2
3
4
COPY 31-12 9-11 8 7 6 5 4 3 2 1 0
+--------------+-------+-----+----+---+---+-----+-----+---+---+---+
| Offset | Avail | MBZ | PS | D | A | PCD | PWT | U | W | P |
+--------------+-------+-----+----+---+---+-----+-----+---+---+---+
-
0 - Present: 表示当前PTE所指向的物理页面是否驻留在内存中
-
1 - Writeable: 表示是否允许读写
-
2 - User: 表示该页的访问所需要的特权级。即User(ring 3)是否允许访问
-
3 - PageWriteThough: 表示是否使用write through缓存写策略
-
4 - PageCacheDisable: 表示是否不对该页进行缓存
-
5 - Access: 表示该页是否已被访问过
-
6 - Dirty: 表示该页是否已被修改
-
7 - PageSize: 表示该页的大小
-
8 - MustBeZero: 该位必须保留为0
-
9-11 - Available: 第9-11这三位并没有被内核或中断所使用,可保留给OS使用。
-
12-31 - Offset: 目标地址的后20位。
因为目标地址以4k作为对齐标准,所以该地址的低12位永远为0,故这12位空间可用于设置标志位。
e. 自映射
-
自映射的好处
- 当页目录与页表建立完成后,如果需要按虚拟地址的地址顺序显示整个页目录表和页表的内容,则要查找页目录表的页目录表项内容,并根据页目录表项内容找到页表的物理地址,再转换成对应的虚地址,然后访问页表的虚地址,搜索整个页表的每个页目录项。这样的过程比较繁琐,而自映射可以改善这个过程。
- 节省4KB空间
- 方便用户态程序访问页表,可以用这种方式实现一个用户地址空间的映射
-
页表自映射的关键点
-
把所有的页表(4KB * 1024个)放到连续的4MB 虚拟地址 空间中,并且要求这段空间4MB对齐,这样,就会有一张虚拟页的内容与页目录的内容完全相同。
-
页目录结构必须和页表结构相同。
-
此时在页目录表中,会存在一个页目录条目,该页目录条目指向某个二级页表。而该二级页表的物理地址,正是页目录表所处于物理页的物理地址。
即,页目录表中存在一个页目录条目,该条目内含的物理地址就是页目录表本身的物理地址。
uCore中的这条代码证实了这个结论:
1 2 3 4 5
COPY// recursively insert boot_pgdir in itself // to form a virtual page table at virtual address VPT // // PDX(VPT)为4MB虚拟页表所对应的PageDirectoryIndex boot_pgdir[PDX(VPT)] = PADDR(boot_pgdir) | PTE_P | PTE_W;
而下面这张图演示了其指向过程:
注意页目录表此时存储于VPT的4MB范围中。
graph LR PDT PT1 PT2/PDT PhyPage1 PhyPage2 PhyPage3/PT1 PhyPage4/PT2 PDT-->PT1 PDT-->PT2/PDT PT1-->PhyPage1 PT1-->PhyPage2 PT2/PDT-->PhyPage3/PT1 PT2/PDT-->PhyPage4/PT2
-
-
参考:页表自映射
5) uCore栈的迁移
-
在原先的lab1中,bootloader所设置的栈起始地址为
0x7c00,之后的uCore的代码也沿用了这个栈,但仍然划分出了一个全局数组作为TSS上的ring0栈地址(该全局数组位于uCore的bss段)。注意此时的两个内核栈是不一样的,一个是中断外使用的栈,另一个是中断内使用的栈。
-
而在lab2中,栈稍微做了一些改变。bootloader所设置的栈起始地址仍然为
0x7c00,但在将uCore加载进内存之后,在kern_entry中,该部分代码在启动页机制后将栈设置为uCore data段上的一个全局数组的末尾地址bootstacktop(8KB),并也在gdt_init将TSS ring0栈地址设置为了bootstacktop。与Lab1不同,之后内核可以使用的内核栈只有一个。
中断处理程序可能会从高地址开始,向下覆盖ring3的栈数据。这个漏洞可能是因为未完全实现的内存管理机制所导致的。
实验结果
实验中涉及的知识点列举
列举本次实验中涉及到的知识点如下:
- 80386 CPU的段页式内存管理机制,以及进入页机制的方法;
- 对物理内存的探测的方法;
- 具体的连续物理内存分配算法,包括first-fit,best-fit等一系列策略;
- ucore中链表的实现方法;
- 在C语言中使用面向对象思想实现物理内存管理器;
- 链接地址、虚拟地址、线性地址、物理地址以及ELF二进制可执行文件中各个段的含义;
对应到的OS中的知识点如下:
- 内存页管理机制;
- 连续物理内存管理;
两者之间的对应关系为:
- 前者为后者提供了具体完成某一个平台上的操作系统对应的内存管理功能的底层支持;
- 同时在实验中设计到的其他一些知识点,比如面向对象思想、链表的使用等,方便了具体的操作系统的实现编码;
实验中未涉及的知识点列举
实验中未涉及的知识点包括:
- 虚拟内存管理,包括在物理内存不足的情况下将暂时使用不到的物理页换出到外存中,从而实现大于物理内存空间的虚拟内存空间;
- PageFault的处理;
- OS中的进程、线程的创建、管理、调度过程,以及进程间的同步互斥;
- OS中用于访问外存的文件系统;
- OS对IO设备的管理;
- 从内核态跳转到用户态的方式;
实验心得
从这次实验中,我对物理内存管理有了一个更好的理解,我们都知道 Linux 操作系统创始人 Linus 曾经说过
Talk is cheap. Show me the code.
我可以说,如果仅仅只是从课本上学理论知识,会做一些题,应付一下考试,这是完全没有什么问题的,你的成绩肯定不会差,但是我想问,这又能学到多少呢?让你自己写一些简单的代码都不会,最多也就只能纸上谈兵罢了
ucore 真的是一个很好地帮助我们理解操作系统的实验,让我们在自己实现动手的时候去理解操作系统,通过做实验指导书上的练习来一步步完善 ucore 操作系统,在这个过程中学习相关知识
在这次 lab2 中,我对物理内存管理有了一个更好的理解,我们都知道有 first fit 、best fit 和 worst fit 等物理内存分配算法,并且通过理论课上的学习,我们也都能知道要怎么做到这些算法,但是我们并没有自己写过 first fit 等物理内存分配算法,只是知道个大概实现的方案,但是通过这次实验的练习一,我完成了 first fit 物理内存分配算法的实现,完成了空闲块管理链表的初始化函数,完成了空闲块的初始化函数,并且完成了内存分配函数和内存释放函数,这样就包括了从内存初始化到内存分配到内存释放整个过程,其他的几种匹配策略我相信只要稍加修改也是一样的。这不仅让我让我知道了要怎么实现这些匹配策略,也让我更加深刻的理解内存分配的整个过程,也弄清楚了这些过程中的一些比较细的点,比如分配的时候也要注意页表中一些状态位的改变
在练习二、练习三中也是让我对虚拟地址通过多级页表转化为物理地址的过程有了一个更加深刻的理解,并且也新了解了一些课本上没有的东西,其实寻址过程大致和课本上的类似,先通过高 10 位地址加上 PDBR 寄存器找到对应的页目录项,然后通过页目录项的高 20 位找到对应的页表,再通过第 12~21 位找到对应的页表项,页表项的高 20 位就是对应的页帧,再加上地址的低 12 位的偏移量就是对应的物理地址
这些其实和教材是差不多的,但是在编程的过程我了解了页目录项和页表项的每一位的用处,只有了解了这些,才能保证代码不会有什么问题
通过扩展练习,我了解了一个新的内存分配算法,也正是 Linux 目前正在使用的分配算法,buddy system(伙伴系统)分配算法,我觉得其中最重要的就是通过完全二叉树进行二分查找来达到 $O(logN)$ 的时间复杂度,并且通过分配 2 的指数大小的内存让内存分配的块比较合适,这里就不细说了,上面有详细的实现方案
参考资料
- https://www.jianshu.com/p/abbe81dfe016
- https://chyyuu.gitbooks.io/ucore_os_docs/content/lab2.html
- https://kiprey.github.io/2020/08/uCore-2/#3-uCore%E7%9A%84%E5%86%85%E5%AD%98%E7%A9%BA%E9%97%B4%E5%B8%83%E5%B1%80
- https://github.com/DelinQu/myCore/tree/master/2
- https://blog.csdn.net/dingdingdodo/article/details/100622753